W14. Основы кэша, конвейеризация ЦП, архитектура GPU
1. Краткое содержание
1.1 Основы кэша
1.1.1 Проблема «стены памяти» (Memory Wall)
Современные системы упираются в узкое место производительности — «Memory Wall»: скорость CPU растёт быстрее, чем скорость доступа к RAM. С 1980-х производительность CPU удваивалась примерно каждые 18–24 месяца (Moore’s Law), а DRAM улучшалась гораздо медленнее, и разрыв processor-memory performance gap только увеличивается.
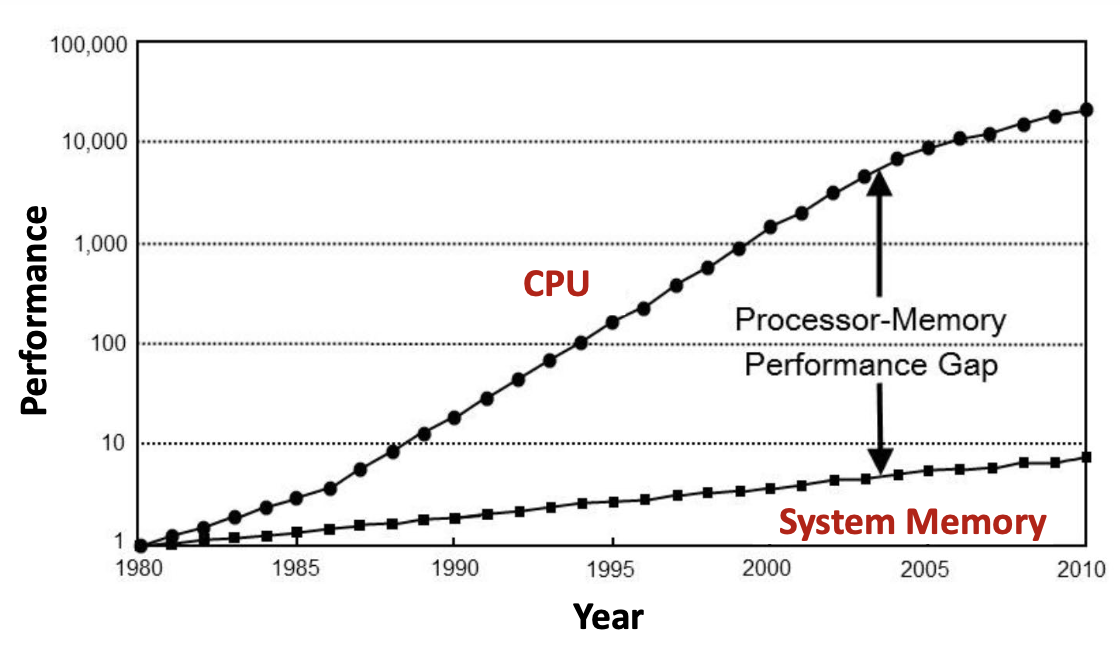
К 2010 году CPU стали примерно в 10 000 раз быстрее, чем в 1980, тогда как память — лишь примерно в 7 раз. Даже самый быстрый CPU часто ждёт данные из относительно медленной основной памяти.
1.1.2 Иерархия памяти
Чтобы смягчить Memory Wall, используют memory hierarchy — уровни памяти с разным компромиссом скорость / ёмкость / стоимость.
Сверху вниз (быстрее → медленнее):
- Регистры CPU — внутри процессора
- Кэш (L1, L2, L3) — небольшой, очень быстрый SRAM
- Оперативная память (RAM) — DRAM, больше объём, ниже скорость
- Накопители (SSD/HDD) — большой объём, низкая скорость, постоянное хранение

Свойства иерархии:
- скорость доступа растёт к CPU;
- ёмкость растёт к устройствам хранения.
Характеристики уровней (порядок величин из оригинала):
- L1: порядка скорости CPU (~100× быстрее RAM), 32–128 KB
- L2: ~25× быстрее RAM, 256–512 KB
- L3: ~2× быстрее RAM, 32–64 MB
- RAM: 18–36 GB/s, 8–32 GB
- SSD: 0.5–2 GB/s, 250–500 GB
1.1.3 SRAM и DRAM
SRAM (Static Random Access Memory):
- применение: регистры и кэш CPU (L1–L3);
- ячейка: триггер (flip-flop / latch);
- очень быстрая, дорогая, меньше плотность, сложнее организация;
- ниже потребление, без утечки заряда как у DRAM;
- обычно надёжнее.
DRAM (Dynamic Random Access Memory):
- применение: основная RAM;
- ячейка: конденсатор;
- медленнее, дешевле, выше плотность, проще организация;
- выше потребление, заметная утечка (нужен refresh);
- менее надёжна в бытовом смысле организации.
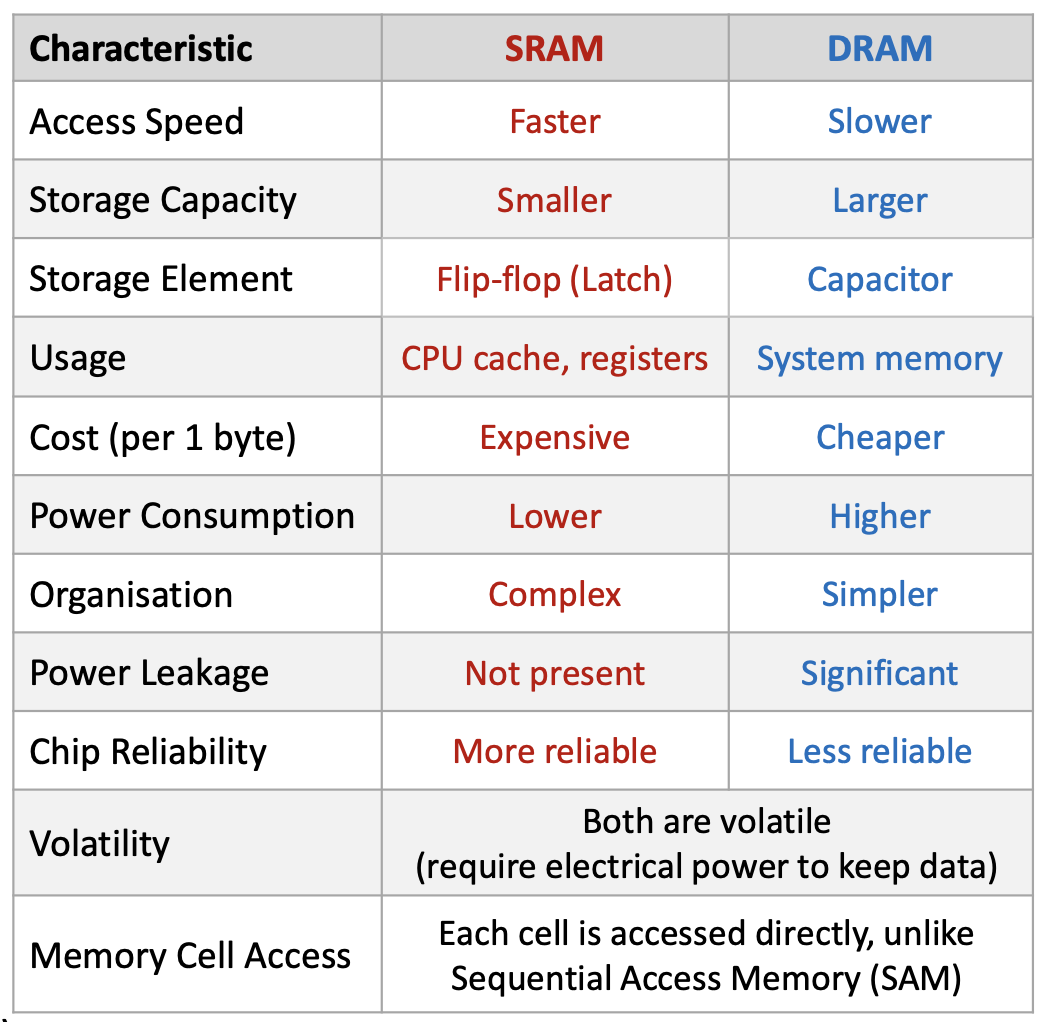
Обе технологии volatile (без питания данные теряются) и дают random access (прямой доступ к адресу, в отличие от ленты и т.п.).
DRAM требует memory controller, который периодически refresh-ит ячейки: заряд на конденсаторе утечет, без подзарядки биты испортятся.
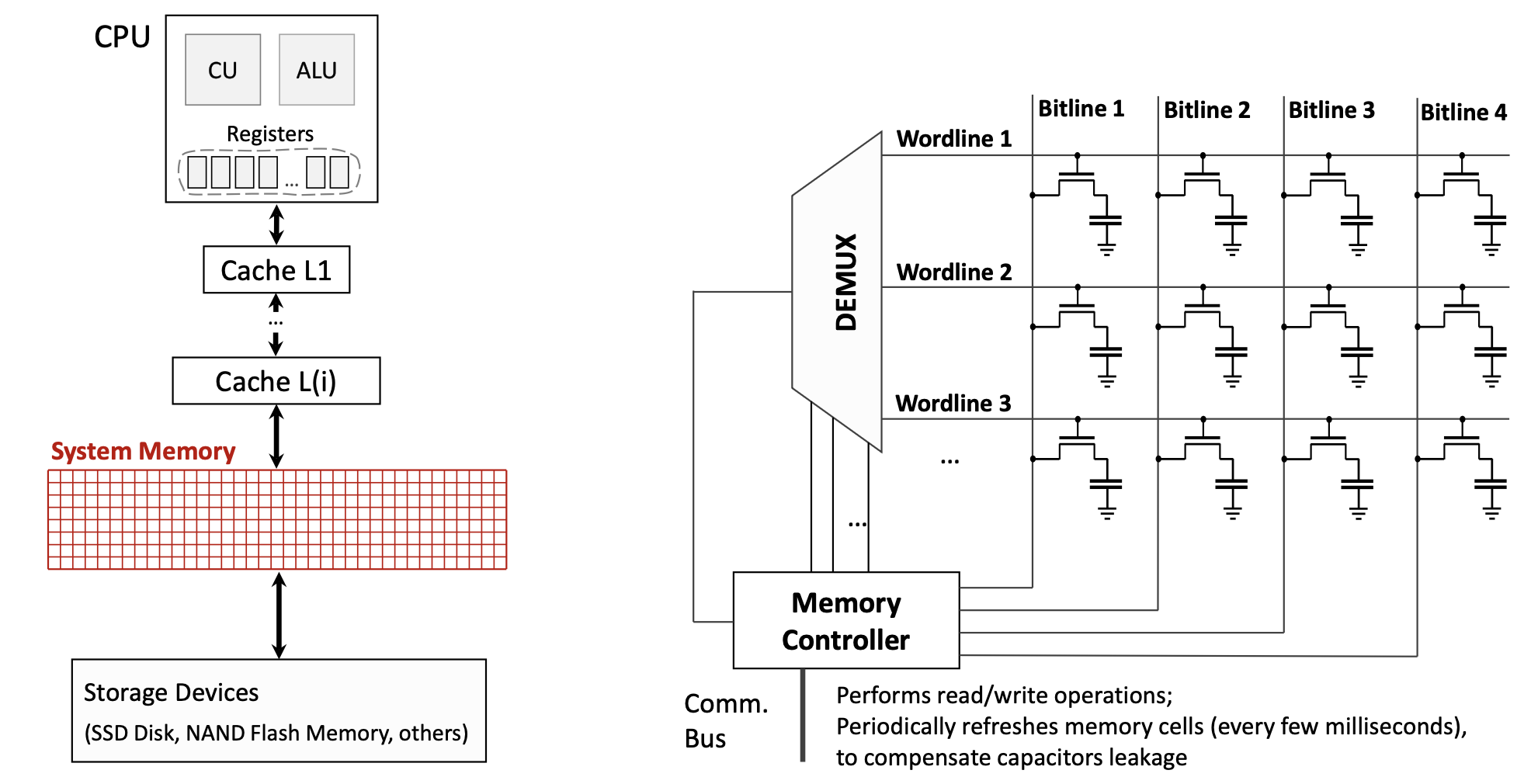
Схема: матрица wordlines и bitlines, в узле — транзистор и конденсатор. Memory Controller управляет чтением/записью и циклами refresh.
1.1.4 Принципы локальности
Иерархия опирается на spatial locality и temporal locality.
Spatial locality: если обратились к адресу \(X\), скоро вероятны обращения к соседним адресам (\(X{+}1\), \(X{+}2\), …) — обход массива, последовательный код.
Temporal locality: если обратились к \(X\), скоро снова обратятся к тому же \(X\) — циклы, часто используемые переменные, повторное использование результата.
Программы в каждый момент активно трогают малую долю адресного пространства — поэтому cache эффективен: недавние и соседние данные держат в быстрой памяти.
Компиляторы усиливают локальность: переупорядочивание инструкций, раскладка структур данных, loop unrolling.
1.1.5 Цель иерархии
Создать иллюзию: «столько памяти, сколько на диске (сотни GB), но со скоростью доступа как у cache у CPU». Работает из‑за локальности: working set держим в кэше, остальное — ниже по иерархии.
1.1.6 Структура кэша и термины
Cache состоит из блоков (cache lines). В блоке:
- Block Index — какая строка кэша (например 00…11 для 4 блоков)
- Validity Flag — валиден ли блок (Y/N)
- Address Tag — старшие биты адреса данных в блоке
- Data Field — копия слов из основной памяти
При обращении к адресу \(A\):
- младшие биты → Block Index;
- старшие → Address Tag;
- tag + index вместе соответствуют полному адресу в модели прямого отображения.
1.1.7 Cache hit и cache miss
Cache hit: данные уже в кэше — флаг валидности Y, tag совпал, данные сразу в регистры, штрафа нет.
Cache miss: блок невалиден или tag не совпал — строка подтягивается с более низкого уровня или из RAM, в кэш копируется целый блок; платим cache miss penalty (латентность, перенос, вставка, выдача слова CPU).
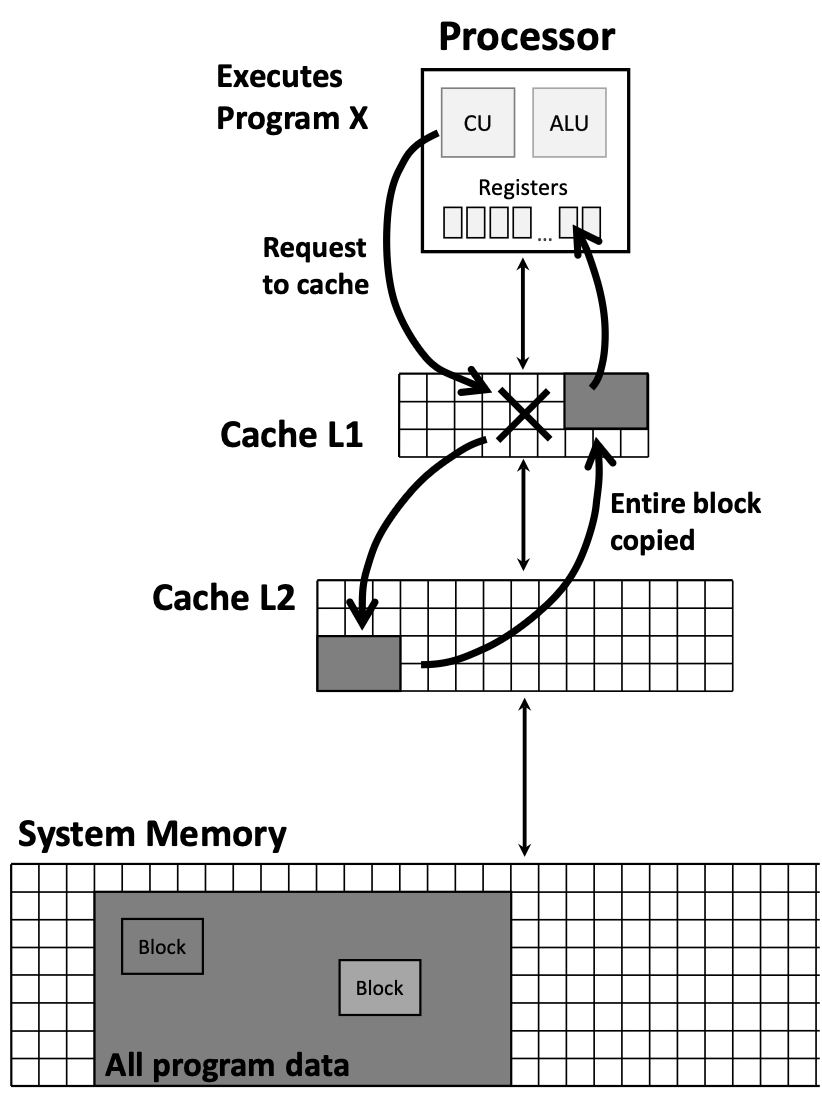
Сначала L1, при промахе — L2, L3, затем RAM; при попадании блок поднимается по иерархии.
1.1.8 Метрики
- Cache hit rate — доля обращений, закрытых кэшем (часто >95%)
- Cache miss rate: \[\text{Miss Rate} = 1 - \text{Hit Rate}\]
- Cache miss penalty — стоимость промаха, порядка ~100 тактов CPU
Даже небольшой miss rate дорог из‑за большого penalty.
1.1.9 Принцип согласованности иерархии
Инвариант: если блок есть в кэше более высокого уровня (например L1), он должен присутствовать и во всех нижележащих уровнях (L2, L3, …) — согласованное представление памяти.
1.1.10 Прямоотображаемый кэш (direct-mapped)
В direct-mapped cache каждый адрес отображается ровно в одну строку; выбор строки — по младшим битам (block index).
Пример: 4 строки, 2 бита индекса — адреса с суффиксами 00, 01, 10, 11 идут в разные строки.
Конфликт: адреса 01010 и 11010 дают один и тот же индекс 10 — взаимные вытеснения и повторные промахи, даже если другие строки пусты.
Альтернатива — fully associative cache: любой блок памяти может занять любую строку; конфликтов меньше, но нужна проверка всех строк за доступ.
1.2 Конвейеризация CPU
1.2.1 Стадии выполнения
Каждая инструкция RISC-V проходит пять стадий:
- IF (Instruction Fetch) — выборка из instruction memory; PC, ~200 ps
- ID (Instruction Decode) — декодирование, чтение регистров; register file, sign-extend, control unit, ~200 ps
- EX (Execution) — ALU, ~200 ps
- MA (Memory Access) — data memory при необходимости, ~200 ps (у ADD нет обращения к памяти)
- WB (Write Back) — запись в регистр, ~200 ps (у store нет WB в регистр результата)
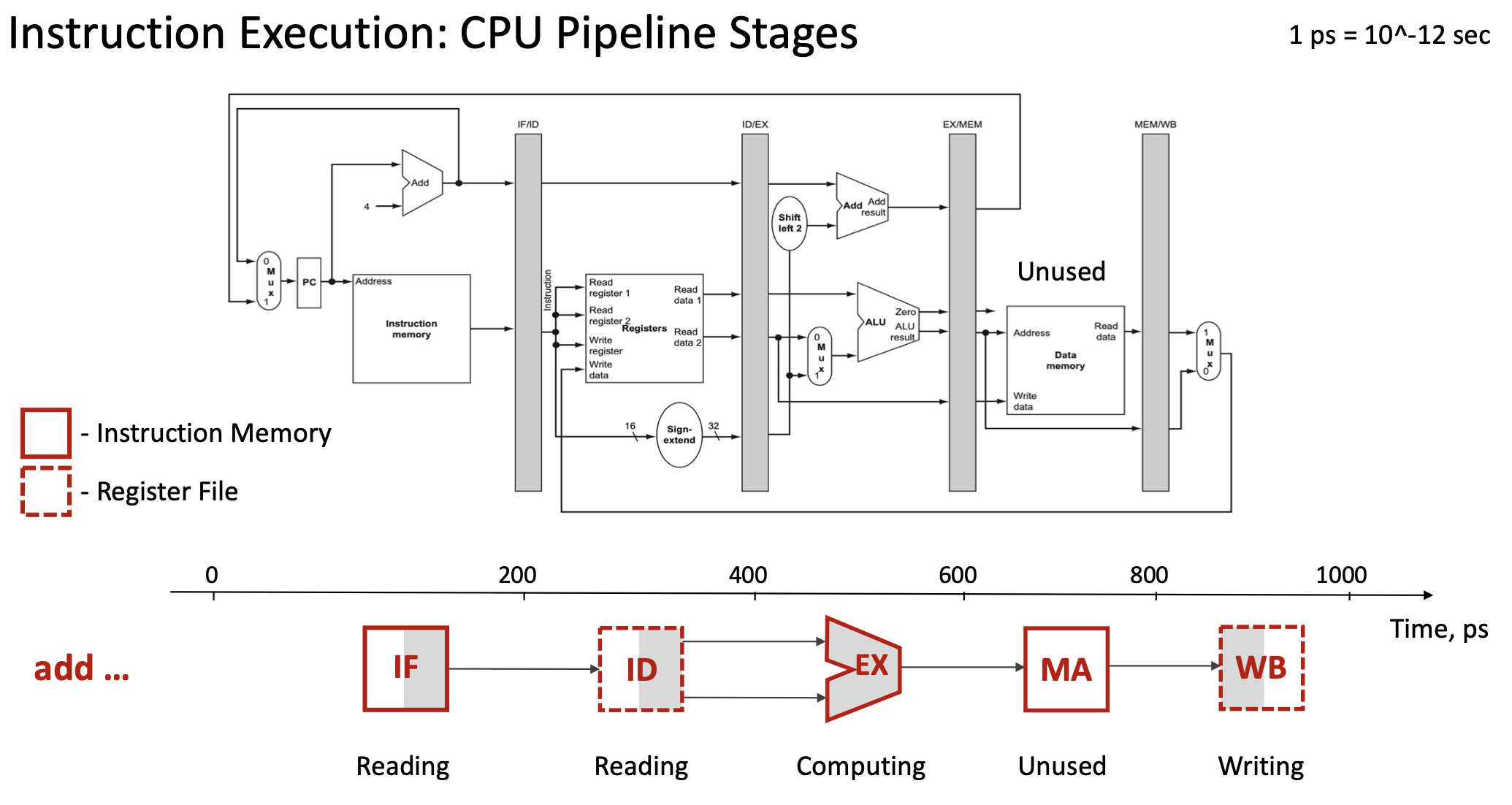
Для одной инструкции add x19, x0, x1 суммарно \(5 \times 200\) ps = 1000 ps (1 ns).
1.2.2 Pipeline registers
Между стадиями стоят pipeline registers (interstage registers):
- IF/ID, ID/EX, EX/MEM, MEM/WB
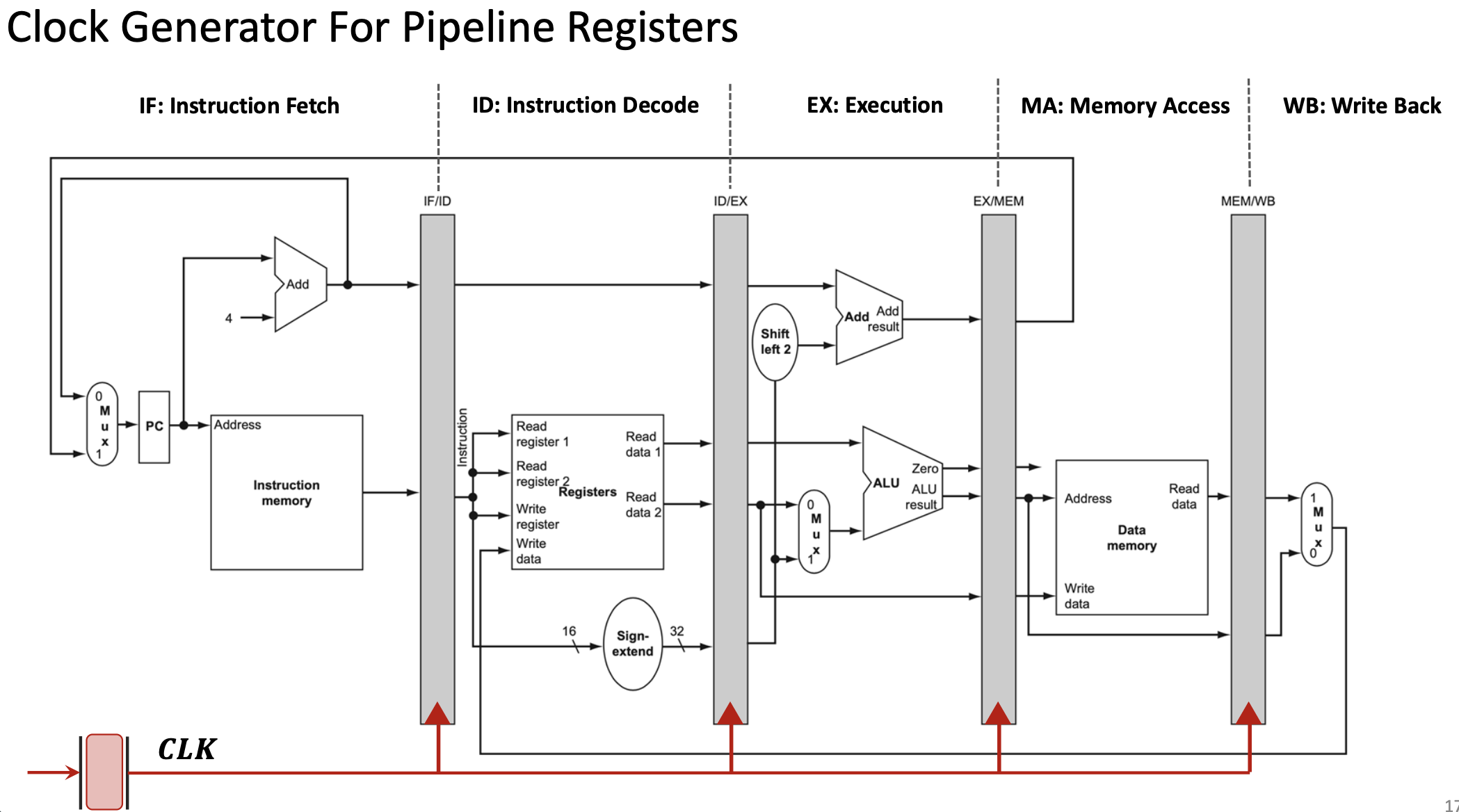
Синхронизация по CLK: на фронте каждый регистр конвейера фиксирует выход предыдущей стадии; все стадии работают параллельно над разными инструкциями.
1.2.3 Идея pipelining
Pipelining — несколько инструкций одновременно на разных стадиях, как конвейер: стадия IF — над инструкцией 5, ID — над 4, …, WB — над 1.
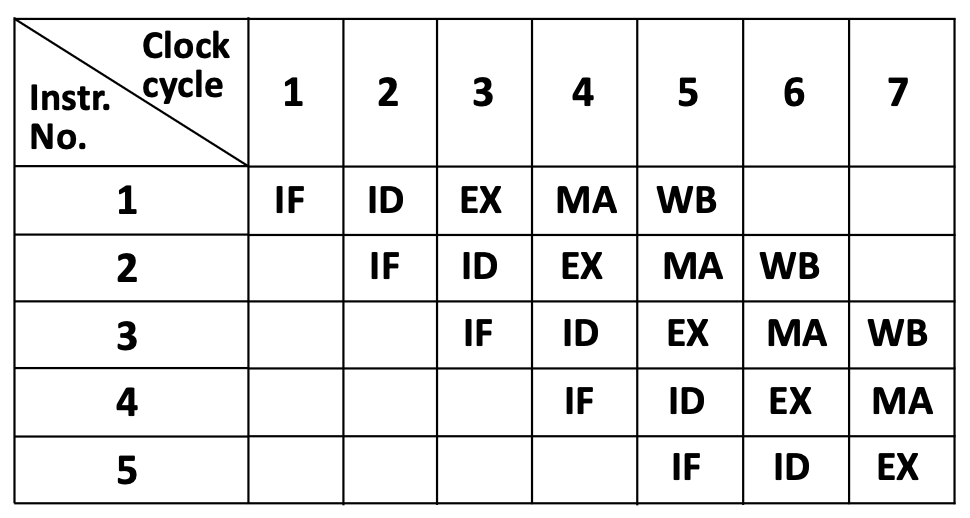
В такте 5 все пять стадий заняты разными инструкциями.
1.2.4 Преимущества
Throughput: одна инструкция всё ещё проходит 5 стадий, но завершений в секунду больше.
- без конвейера: 1 инструкция / 1000 ps ⇒ \(10^9\) инструкций/с;
- с 5 стадиями после заполнения: 1 инструкция / 200 ps ⇒ \(\approx 5 \times 10^9\) инструкций/с.
Теоретически ускорение до числа стадий; на практике 3–4× из‑за hazards и накладных расходов.
1.2.5 Принципы RISC-V для конвейера
Фиксированная длина 32 бита — IF всегда читает 4 байта.
Мало форматов, поля на одних позициях — ID может начать декод до полной классификации.
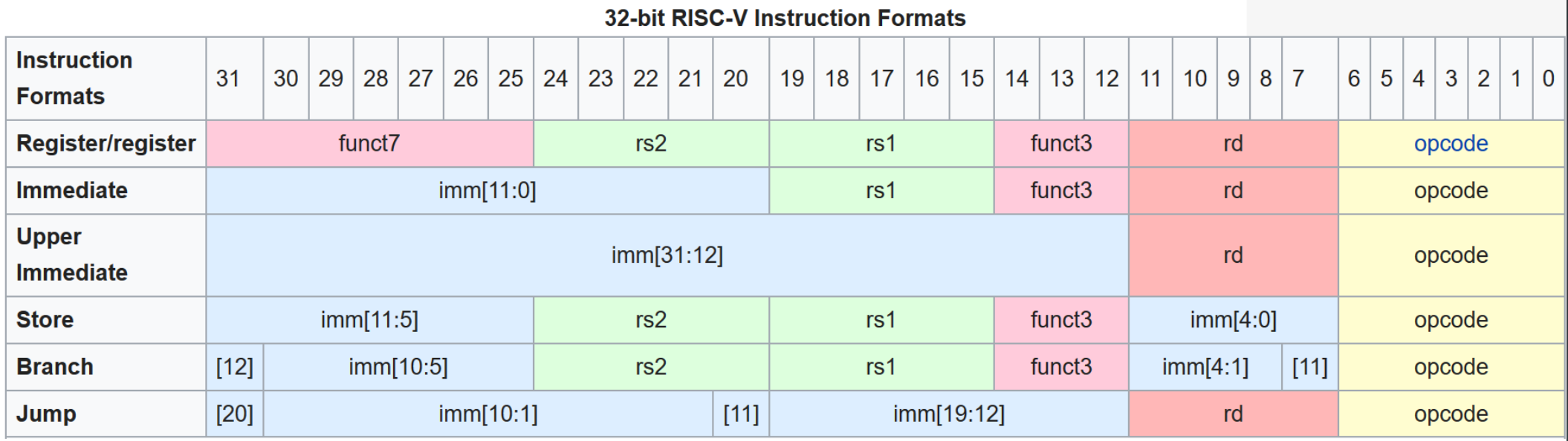
Шесть форматов (R, I, S, B, U, J); opcode, rd, rs1, rs2 на фиксированных битах.
Память только у load/store — стадию MA обходят большинство инструкций.
1.2.6 Pipeline hazards
Hazards — ситуации, когда следующая инструкция не может корректно войти в такт.
Пример data hazard:
A: add x19, x0, x1 // x19 = x0 + x1
B: sub x2, x19, x3 // x2 = x19 - x3B зависит от результата A: A пишет x19 в WB (такт 5), а B читает x19 уже в ID (такт 3).
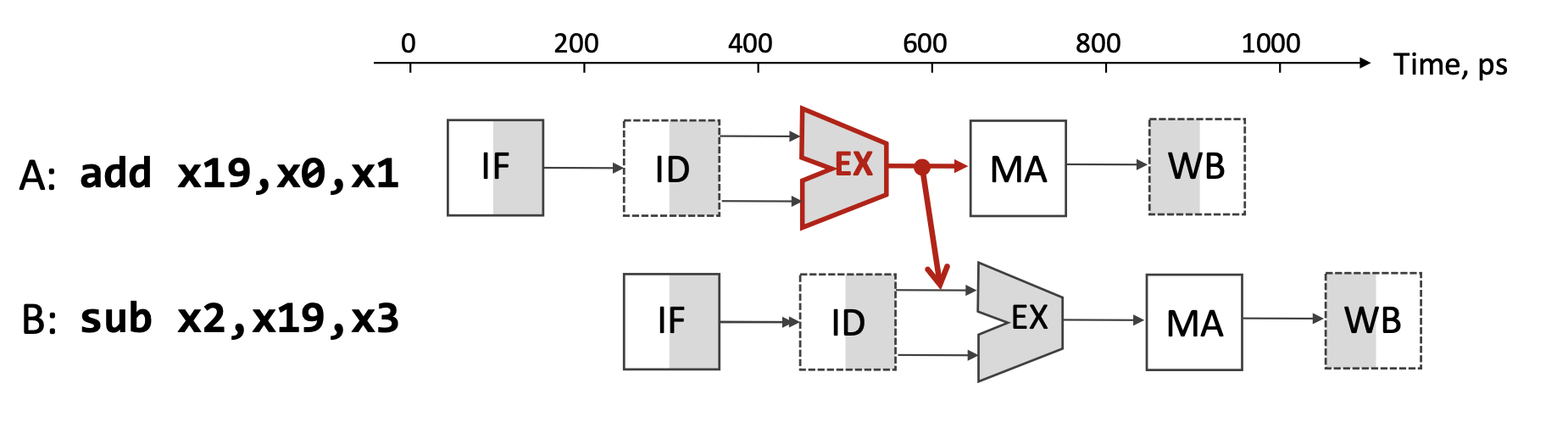
Решения:
- Stall / pipeline bubble — пауза B до WB A; теряются такты.
- Forwarding (bypassing) — после EX A результат сразу идёт на вход EX B, минуя регистровый файл.
- Compiler instruction reordering — между A и B вставляют независимые инструкции.
1.2.7 Оптимизация компилятором
a = b + e;
c = b + f;Наивный ассемблер (есть stall из‑за load-use):
lw x1, 0(x31) // Load b
lw x2, 8(x31) // Load e
add x3, x1, x2 // Stall waiting for x1, x2
sw x3, 24(x31) // Store a
lw x4, 16(x31) // Load f
add x5, x1, x4 // Stall waiting for x4
sw x5, 32(x31) // Store cПереупорядоченный (третий load раньше заполняет «дыру» после двух lw):
lw x1, 0(x31) // Load b
lw x2, 8(x31) // Load e
lw x4, 16(x31) // Load f (moved up!)
add x3, x1, x2 // No stall—x1, x2 are ready
sw x3, 24(x31) // Store a
add x5, x1, x4 // No stall—x1, x4 are ready
sw x5, 32(x31) // Store c1.3 Архитектура GPU и параллельные вычисления
1.3.1 Классификация Флинна (Flynn’s Taxonomy)
Michael Flynn (1966, 1972): потоки команд и данных.
| Архитектура | Команды | Данные | Описание |
|---|---|---|---|
| SISD | Single | Single | классический скалярный CPU |
| SIMD | Single | Multiple | одна команда — много элементов данных (vector, GPU) |
| MISD | Multiple | Single | редко; отказоустойчивость |
| MIMD | Multiple | Multiple | независимые cores, разные потоки команд и данных |
Сегодня: SISD (одно ядро), SIMD (GPU, SSE, AVX), MIMD (мультиядерность), SIMT (Single Instruction Multiple Threads, вариант у NVIDIA).
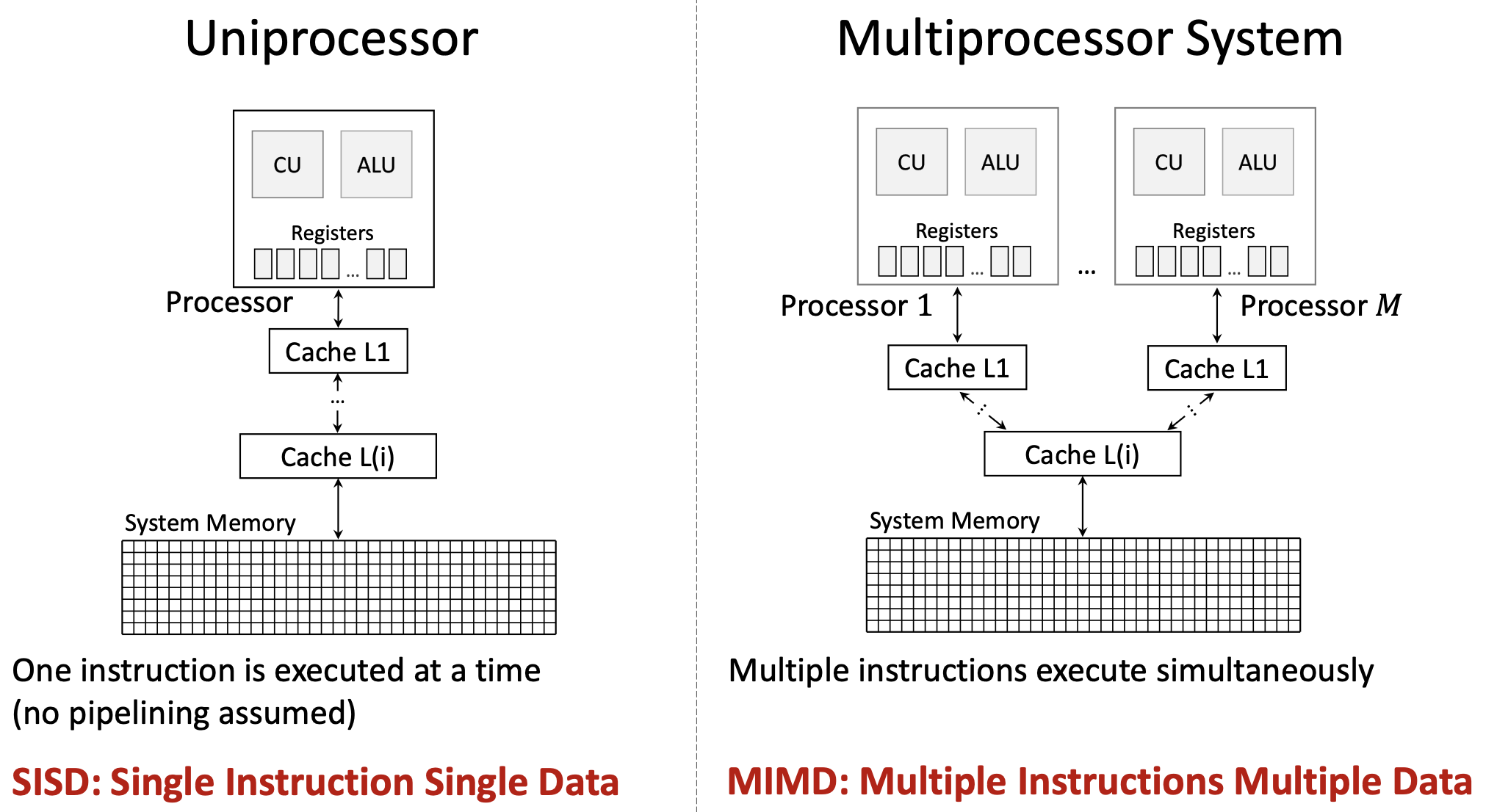
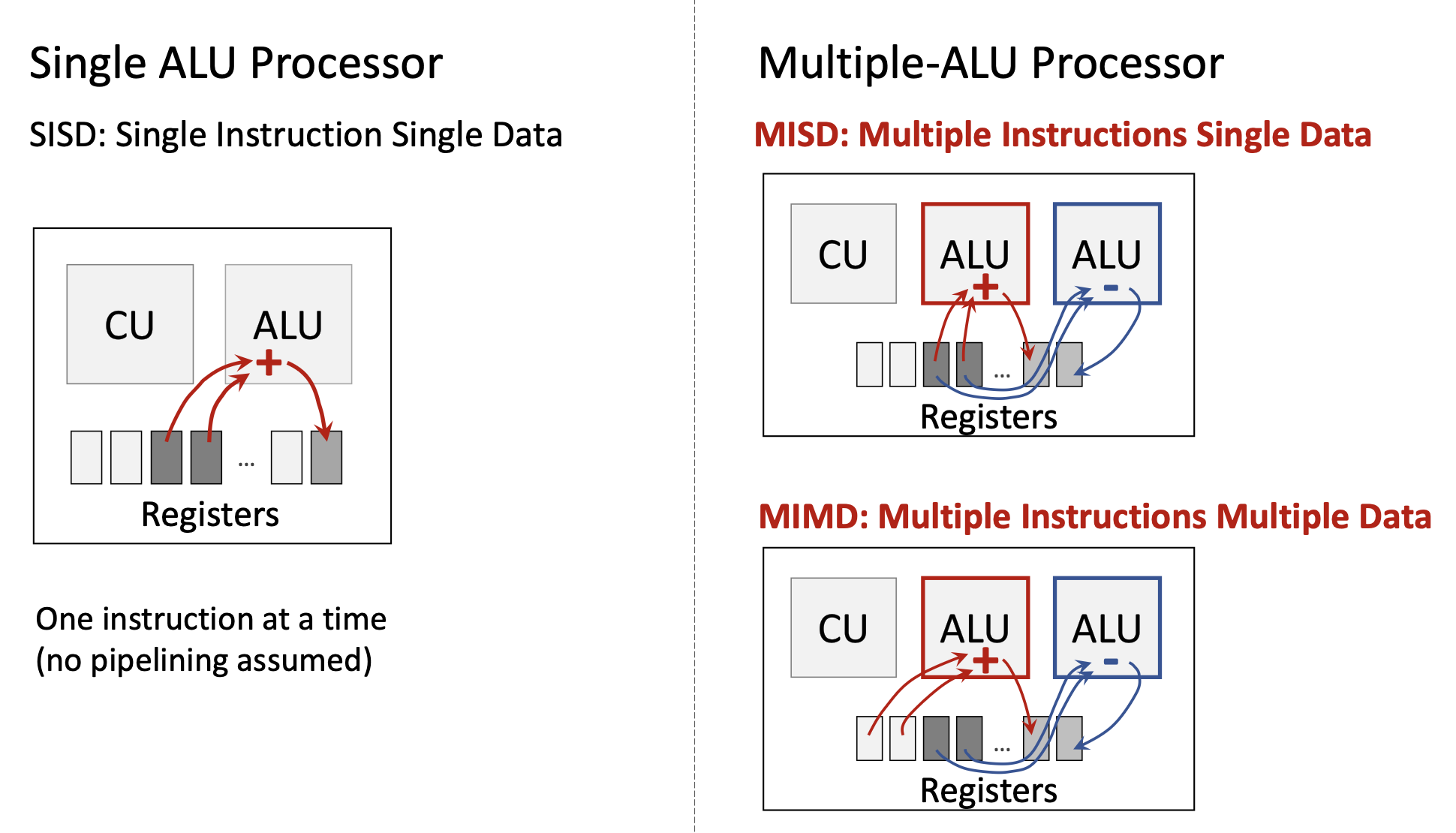
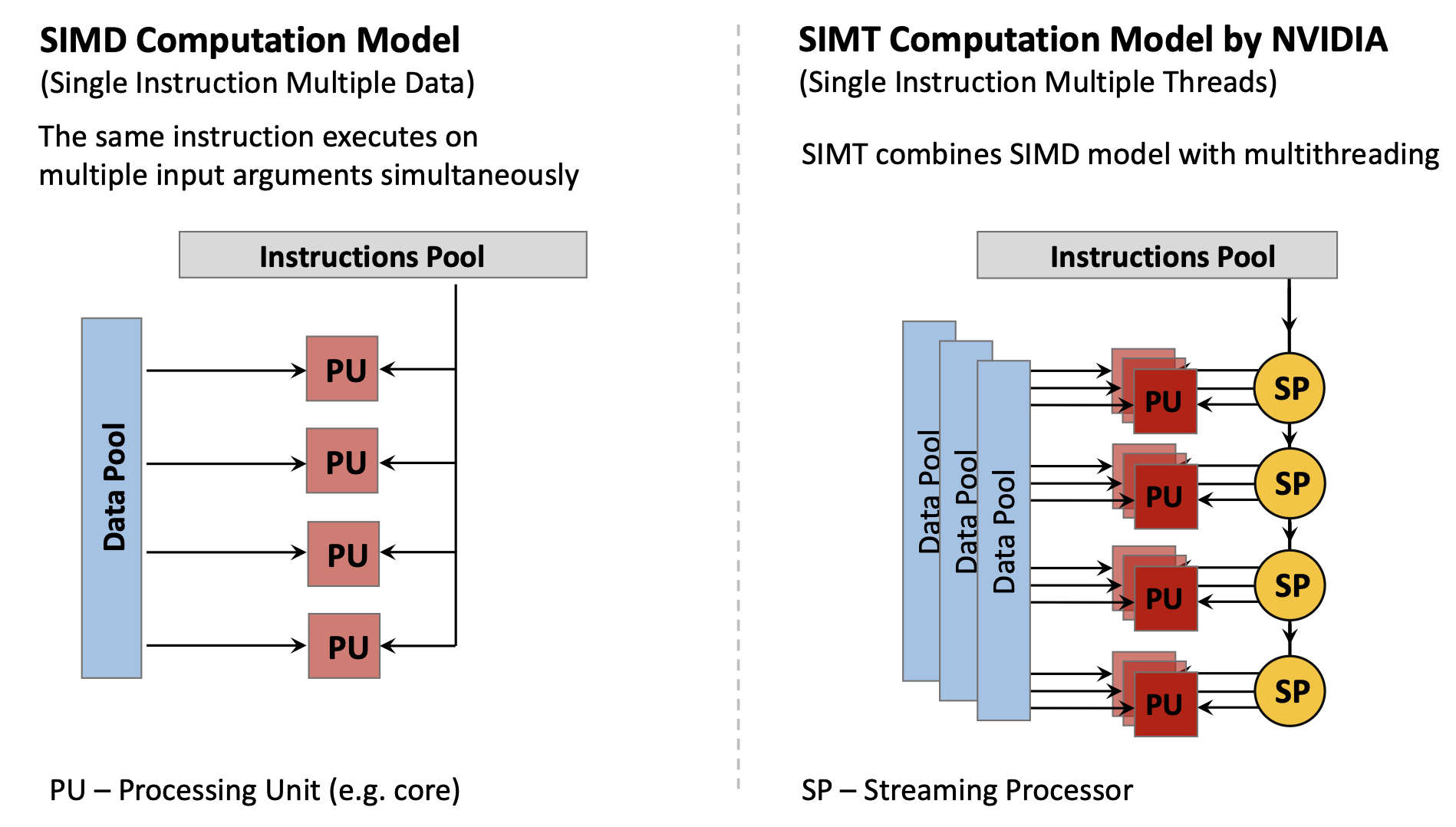
1.3.2 Философия CPU vs GPU
CPU (latency-optimized): сложное управление, большой кэш, мало мощных ядер, низкая задержка на поток; аналогия — «спорткар» для пары пассажиров.
GPU (throughput-optimized): простые команды, мало кэша, упор на полосу памяти, тысячи простых ядер; аналогия — «автобус» для многих задач сразу; throughput по «пассажиро-км/ч» может быть выше.
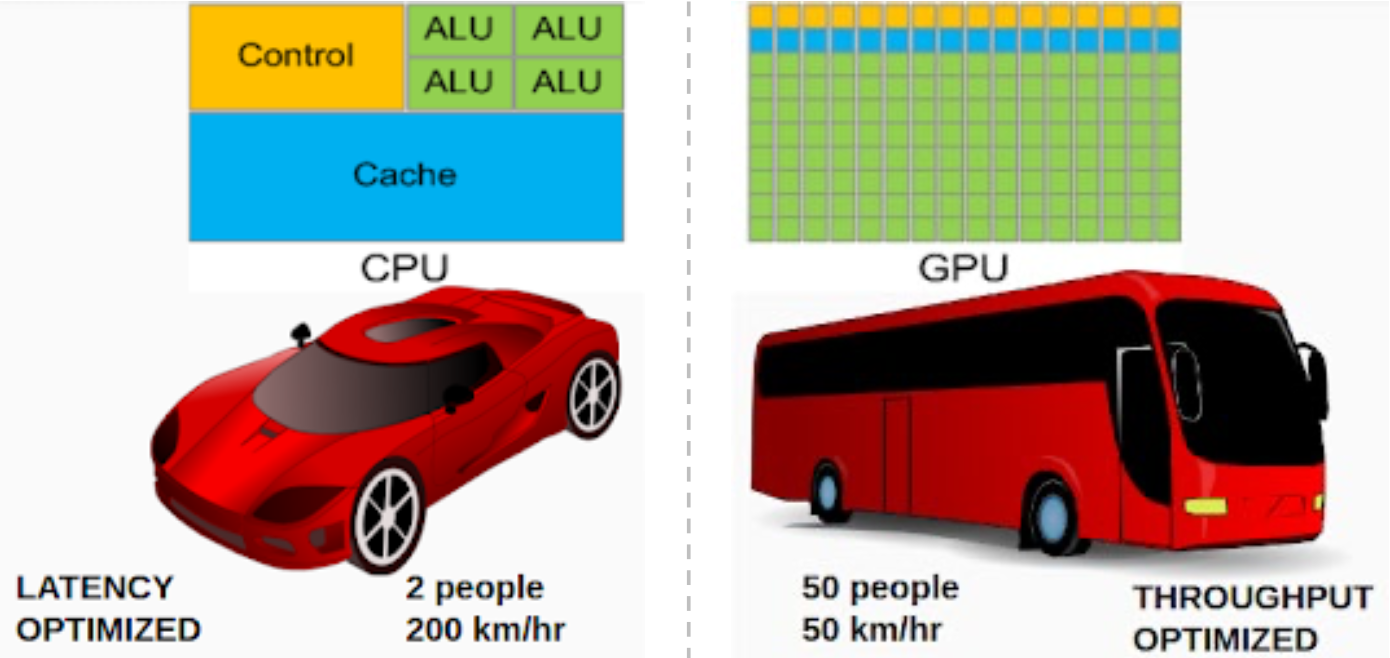
1.3.3 Memory Wall и GPU
Та же Memory Wall, что и для кэшей, мотивирует GPU, но иначе:
- CPU — глубокая иерархия кэшей, скрытие задержки;
- GPU — массовый параллелизм: пока часть threads ждёт память, остальные считают.
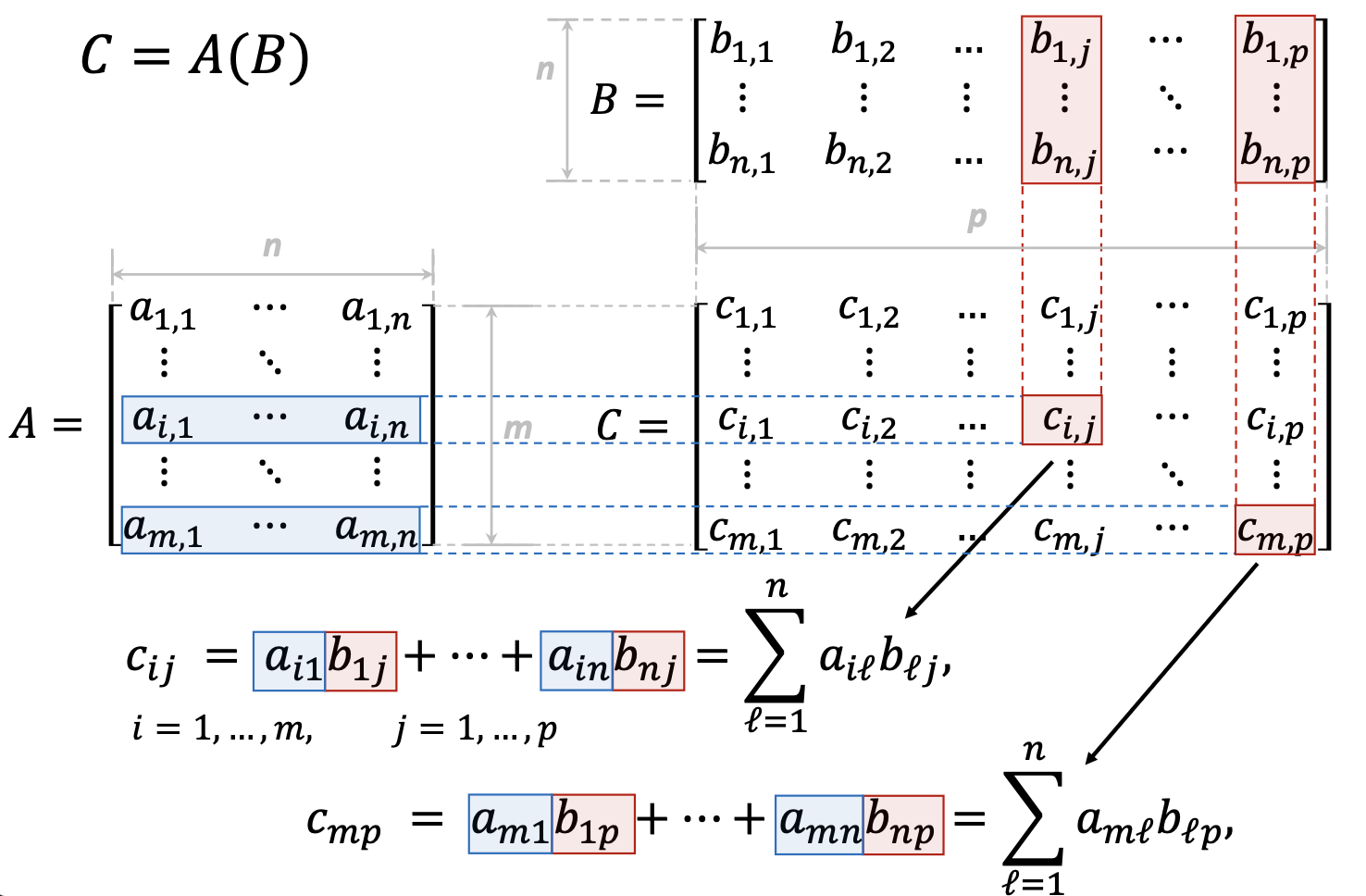
1.3.4 Матрицы как мотивация GPU
\(C = AB\):
\[c_{ij} = \sum_{\ell=1}^{n} a_{i\ell} b_{\ell j}\]
Элементы \(c_{ij}\) независимы, операция одна (multiply-accumulate), элементов много — хорошо ложится на SIMD.
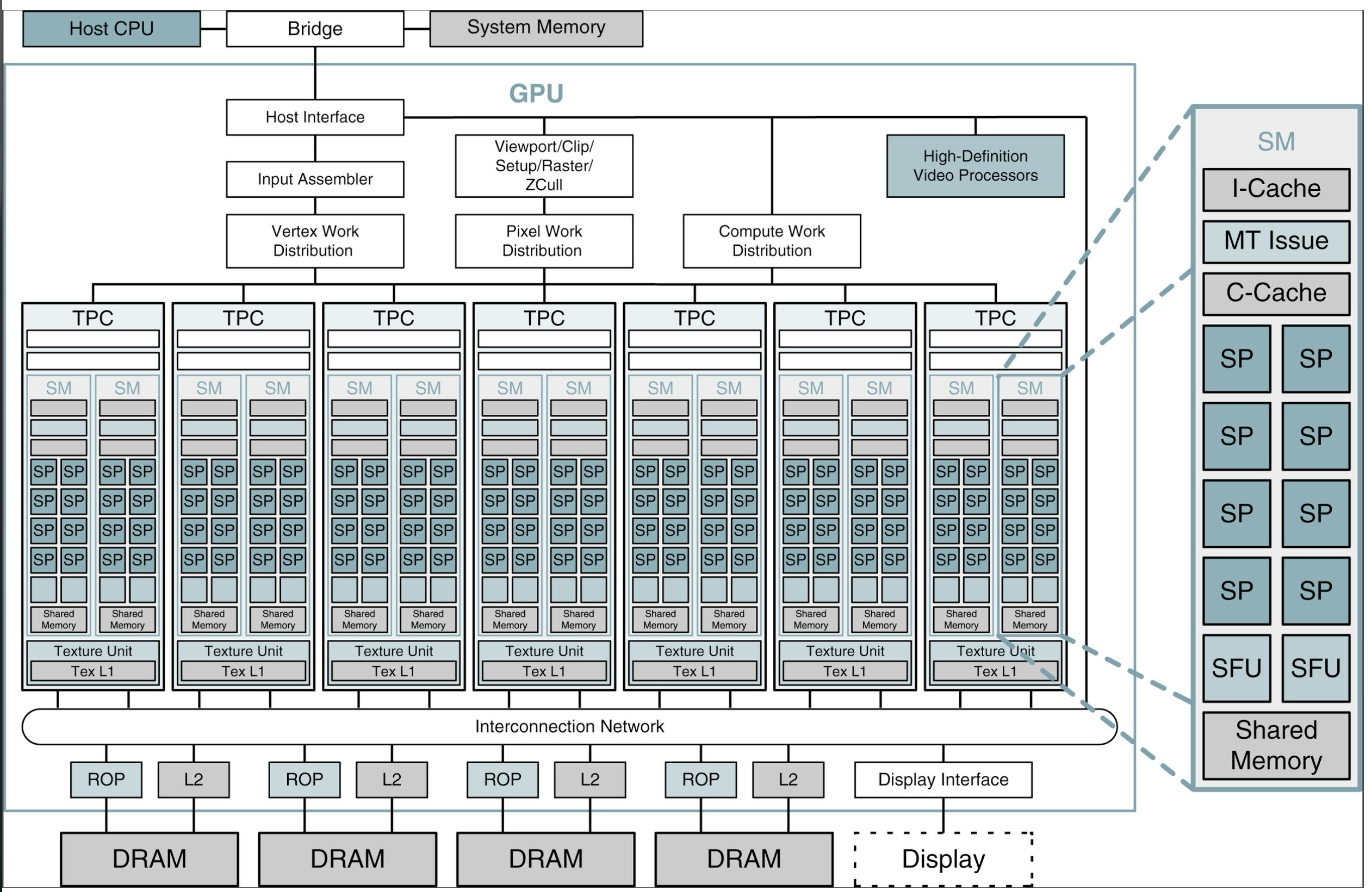
1.3.5 Пример NVIDIA (Tesla / GeForce 8800)
- 14 Streaming Multiprocessors (SM);
- по 8 Streaming Processors (SP) на SM;
- 112 SP всего;
- до 10 752 активных threads.
На SM: несколько SP, shared memory, I-Cache, C-Cache, SFU (sin, cos, …).
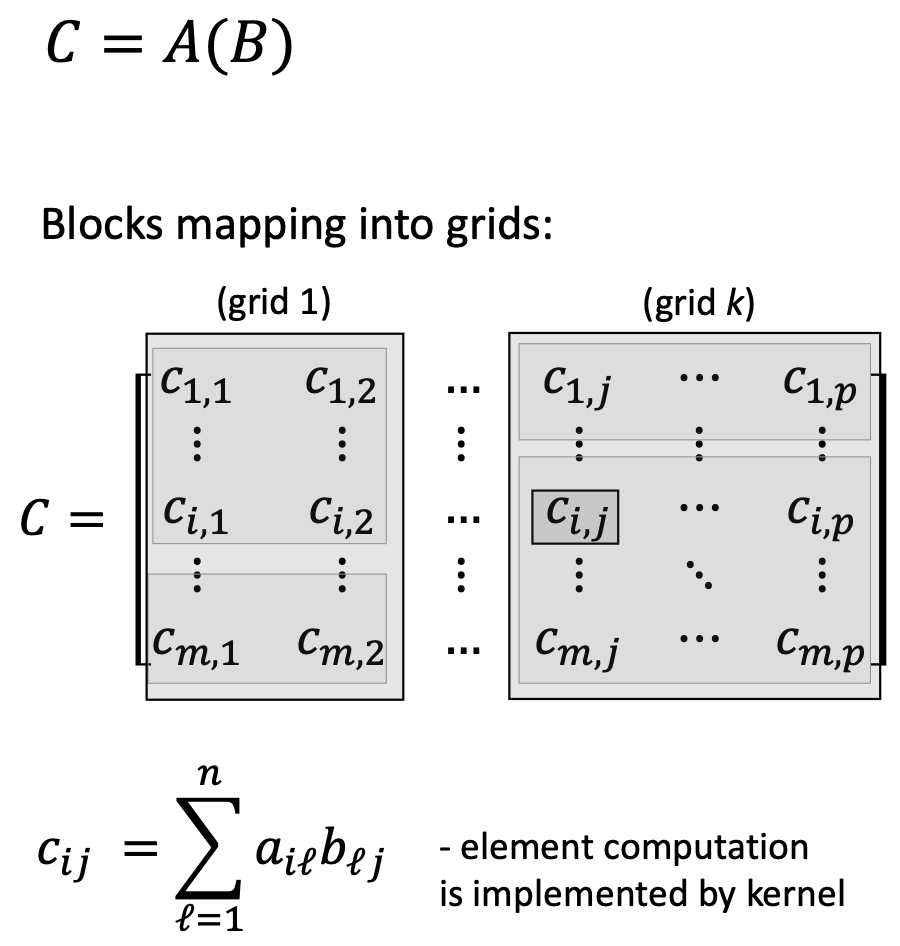
1.3.6 Модель CUDA
CUDA (Compute Unified Device Architecture) — как программные сущности отображаются на железо:
Иерархия ПО:
- Kernel — функция на GPU для многих элементов данных
- Thread — одно выполнение kernel
- Thread block — группа threads с общей памятью
- Grid — набор blocks с одним kernel
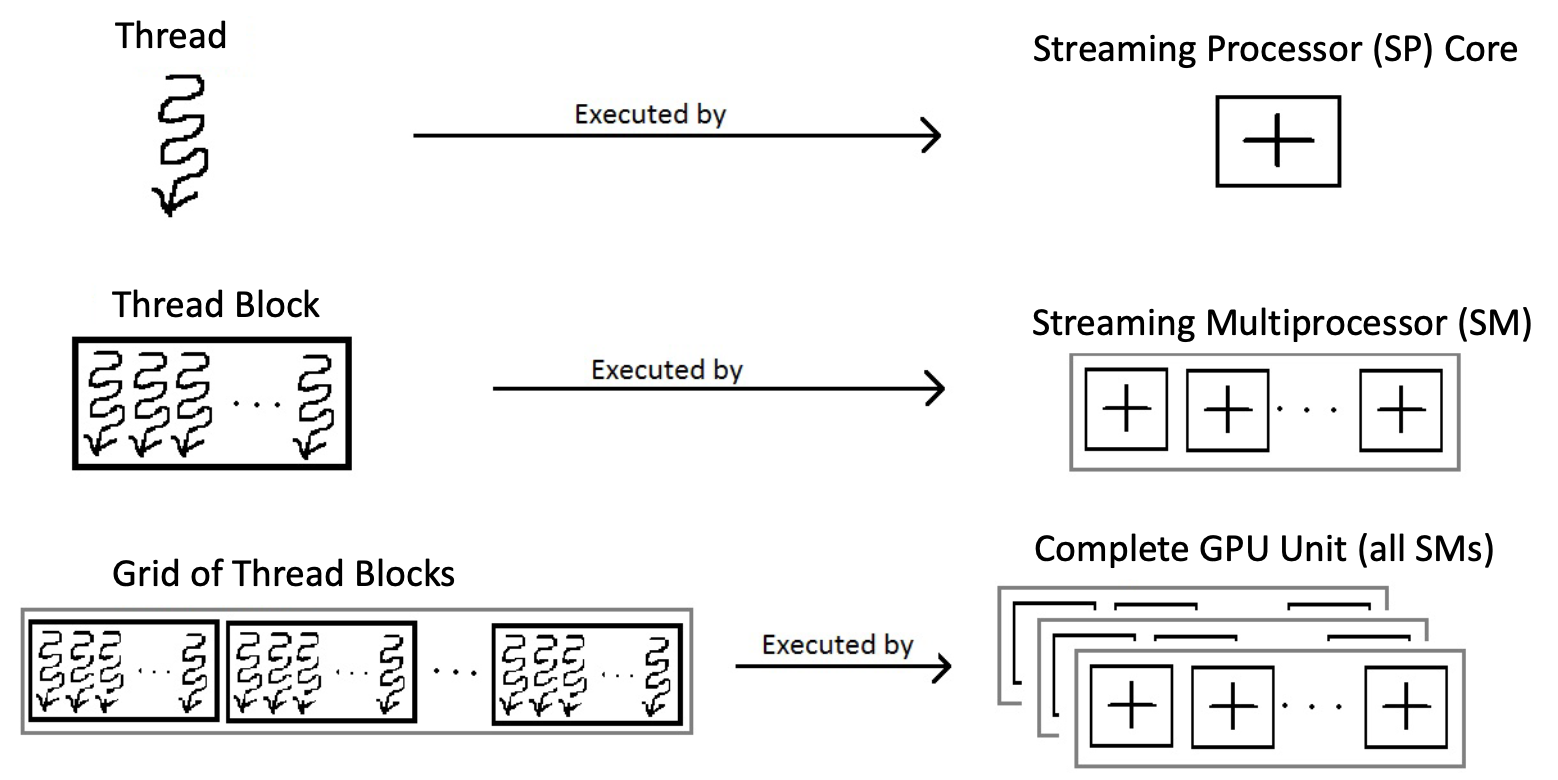
Соответствие железу:
- Thread → один SP core
- Thread block → один SM
- Grid → весь GPU
Для \(C=AB\) размера \(m \times p\): каждый \(c_{ij}\) — отдельный thread; blocks (например \(16\times 16\)); grid покрывает \(C\).
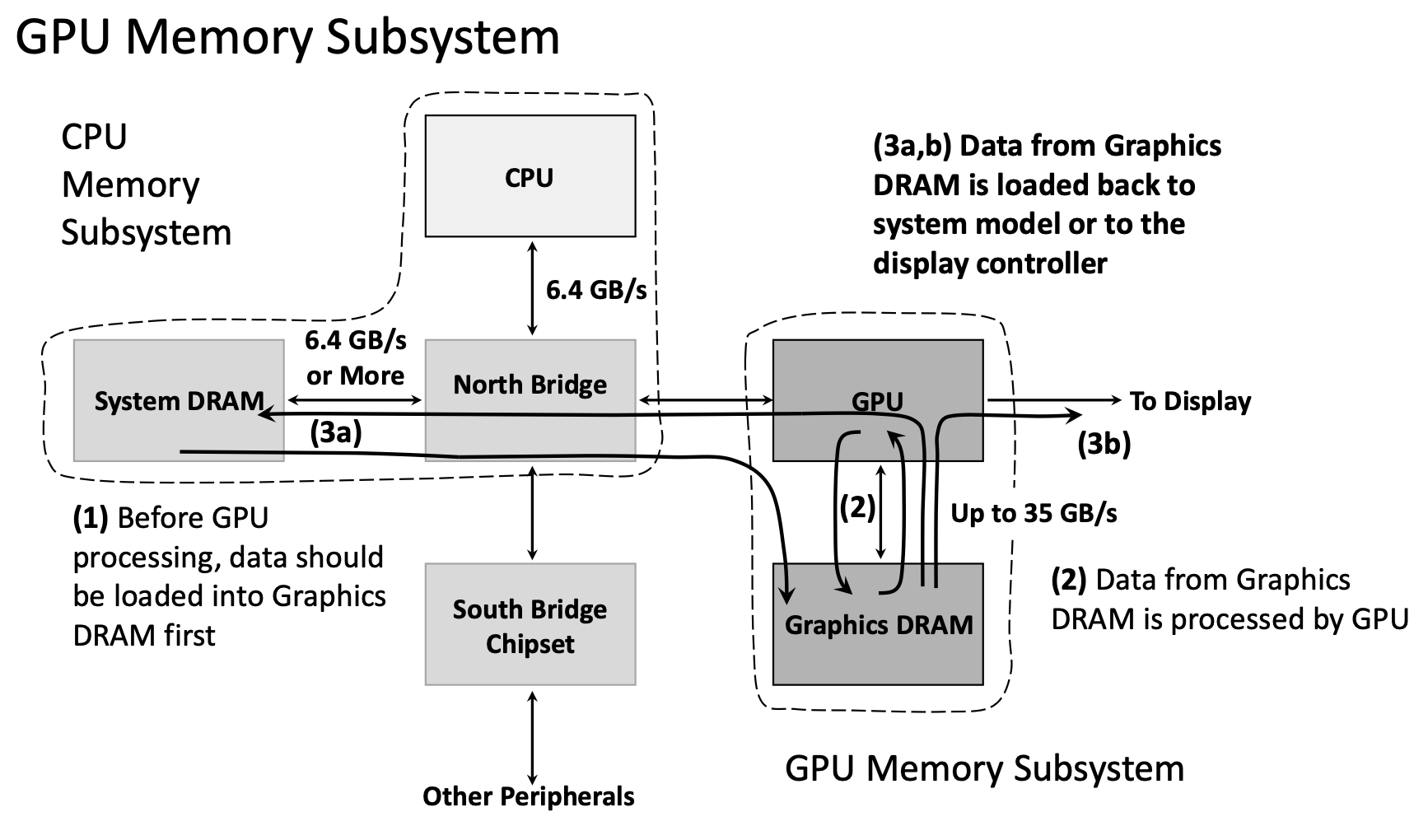
1.3.7 Память CPU и GPU
CPU: системная DRAM (8–32 GB), связь через North Bridge, ~6.4 GB/s.
GPU: выделенная graphics DRAM (4–24 GB), шина к GPU, до ~35 GB/s и выше на новых чипах.
Поток данных: выделение на CPU → копирование Host→GPU → счёт на GPU → копирование обратно. Узкое место часто PCIe/копирование, а не сами ALU GPU.
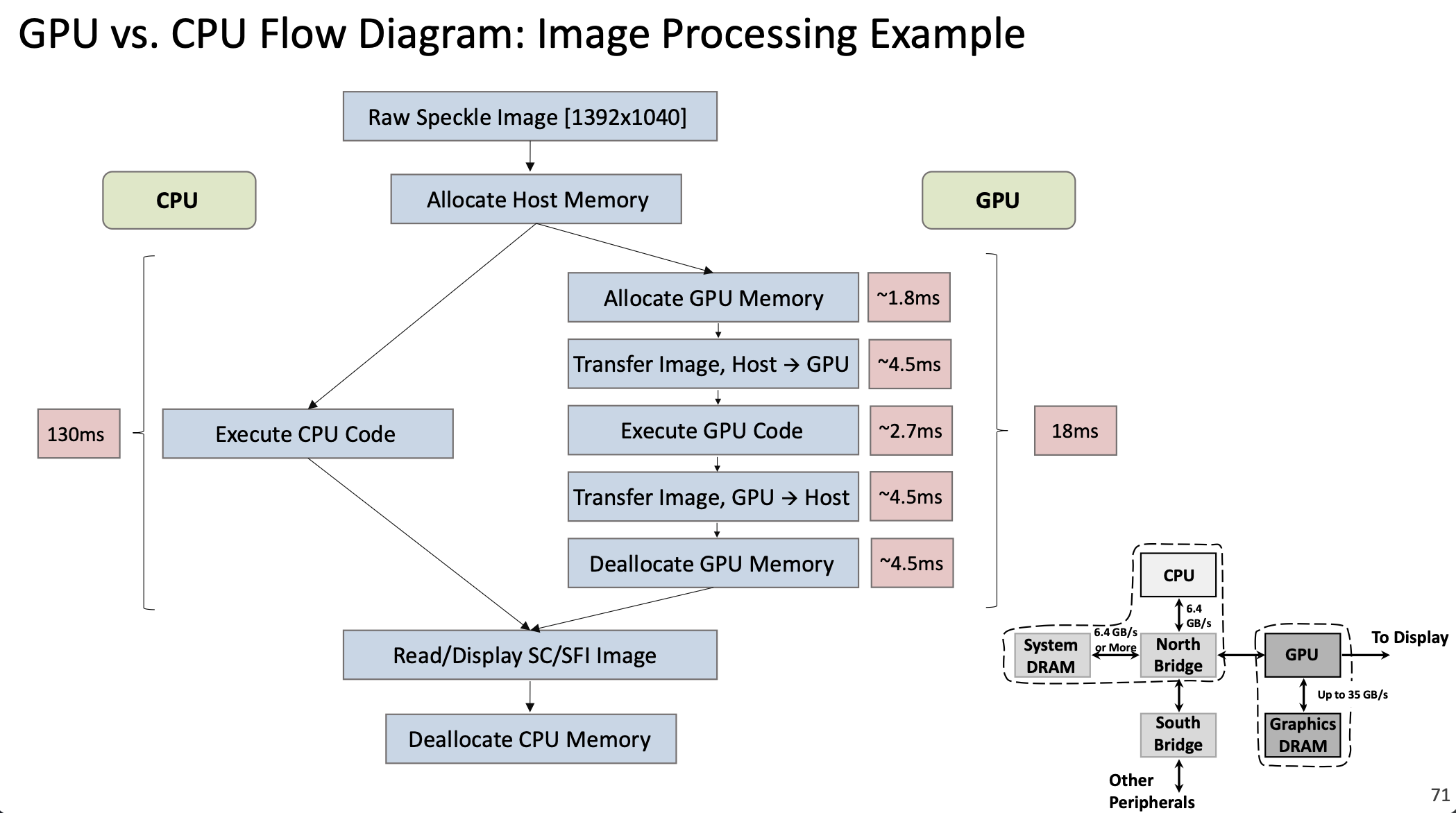
1.3.8 Пример производительности
Изображение 1392×1040: CPU ~130 ms; GPU (аллокация, два переноса, kernel, деаллокация) ~18 ms — примерно 7× быстрее; на больших задачах и при данных на GPU часто 30–100×.
1.3.9 Применения GPU
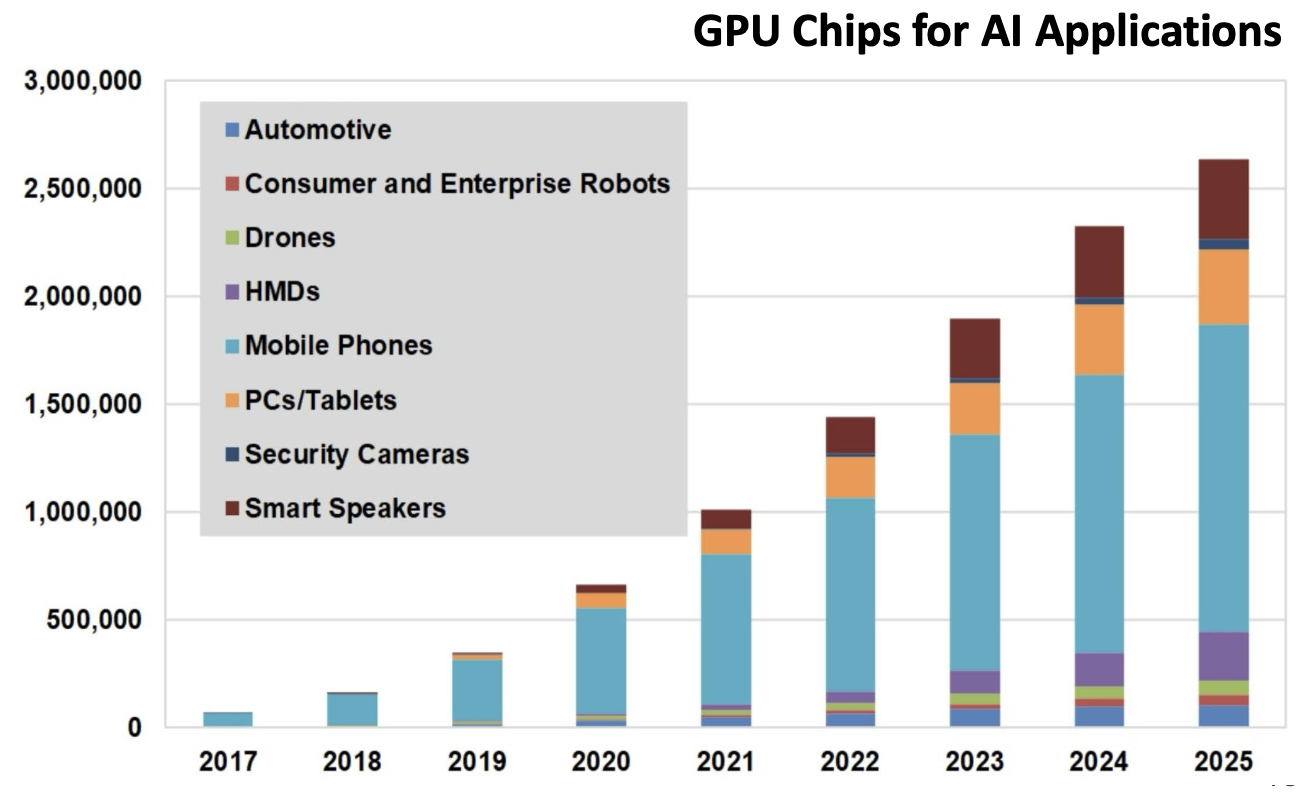
Графика; GPGPU: физика, климат, химия; ML/AI (обучение и инференс — в основном матрицы; рынок AI-GPU вырос с <100K шт. (2017) до >2.5M прогноза к 2025); видео/медицина; криптография; финансы (Monte Carlo).
Почему GPU сильны в AI: сети — большие матрицы; одинаковые операции на миллионах образцов (SIMD-паттерн); высокий TFLOPS; лучше соотношение цена/производительность, чем у CPU, на таких нагрузках.
1.3.10 Инструменты
CUDA, OpenCL, ROCm, SYCL.
// CPU version
void saxpy_serial(int n, float a, float *x, float *y) {
for (int i = 0; i < n; ++i)
y[i] = a * x[i] + y[i];
}
// GPU version
__global__ void saxpy_parallel(int n, float a, float *x, float *y) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) y[i] = a * x[i] + y[i];
}Ключевое слово __global__ задаёт kernel; индекс i из blockIdx, blockDim, threadIdx.
1.3.11 Ускорители кроме GPU
TPU, NPU, FPGA, доменно-специальные чипы — тренд к heterogeneous computing: CPU + специализированные ускорители.
2. Определения
- Cache: быстрая память малого объёма с копиями часто используемых данных из RAM.
- Cache Block (Cache Line): минимальная единица переноса между кэшем и памятью.
- Block Index: часть адреса — номер строки кэша (младшие биты).
- Address Tag: старшие биты адреса, хранимые в строке.
- Validity Flag: признак валидности строки.
- Cache Hit: данные найдены в кэше.
- Cache Miss: данных нет — обращение ниже по иерархии.
- Cache Miss Penalty: время и стоимость подкачки блока.
- Cache Hit Rate: доля попаданий.
- Cache Miss Rate: \(1 - \text{Hit Rate}\).
- Spatial locality: соседние адреса скоро понадобятся.
- Temporal locality: тот же адрес скоро снова.
- Direct-Mapped Cache: один адрес → одна строка.
- Fully Associative Cache: любой блок — в любую строку.
- Memory Consistency Principle: наличие в верхнем уровне ⇒ наличие во всех нижних.
- SRAM (Static RAM): на триггерах; кэш и регистры.
- DRAM (Dynamic RAM): на конденсаторах; RAM с refresh.
- Pipeline: перекрытие инструкций на стадиях.
- Pipeline Stages: IF, ID, EX, MA, WB.
- Pipeline Registers: регистры между стадиями.
- Data Hazard: зависимость от ещё не готового результата.
- Forwarding (Bypassing): проброс результата между стадиями.
- Pipeline Stall (Bubble): пустой такт из‑за hazard.
- Throughput: инструкций в единицу времени.
- Flynn’s Taxonomy: SISD, SIMD, MISD, MIMD.
- SISD / SIMD / MIMD: как в таблице Флинна.
- GPU (Graphics Processing Unit): массив простых ядер, throughput.
- Streaming Multiprocessor (SM): кластер SP, исполняет thread block.
- Streaming Processor (SP) Core: вычислительное ALU внутри SM.
- Kernel: функция на GPU для многих точек данных.
- Thread / Thread Block / Grid: модель CUDA.
- CUDA (Compute Unified Device Architecture): платформа NVIDIA.
- GPGPU: вычисления на GPU не только для графики.
- Heterogeneous Computing: CPU + ускорители (GPU, TPU, …).
3. Примеры
3.1. Трассировка direct-mapped кэша (Лекция 12, Пример 1)
Прямоотображаемый кэш: 4 строки (2 бита index), адресное пространство 5 бит (32 ячейки). Изначально Validity = N. Последовательность:
LW 01010LW 01100LW 01010LW 11010LW 01010
Для каждого шага: hit или miss и состояние кэша.
Нажмите, чтобы увидеть решение
Ключевая идея: адрес делится на Block Index (младшие биты) и Address Tag; hit, если строка валидна и tag совпал.
Разбиение адреса (5 бит, 2 бита индекса):
- биты [1:0]: Block Index
- биты [4:2]: Address Tag
Начальное состояние:
| Block Index | Validity | Tag | Data |
|---|---|---|---|
| 00 | N | — | — |
| 01 | N | — | — |
| 10 | N | — | — |
| 11 | N | — | — |
Доступ 1: LW 01010
01010→ Tag010, Index10- строка
10: N - MISS
- загрузить \(W_{01010}\) в строку
10
Состояние кэша после доступа 1:
| Block Index | Validity | Tag | Data |
|---|---|---|---|
| 00 | N | — | — |
| 01 | N | — | — |
| 10 | Y | 010 | \(W_{01010}\) |
| 11 | N | — | — |
Доступ 2: LW 01100
01100→ Tag011, Index00- строка
00: N - MISS
- загрузить \(W_{01100}\) в строку
00
Состояние кэша после доступа 2:
| Block Index | Validity | Tag | Data |
|---|---|---|---|
| 00 | Y | 011 | \(W_{01100}\) |
| 01 | N | — | — |
| 10 | Y | 010 | \(W_{01010}\) |
| 11 | N | — | — |
Доступ 3: LW 01010
- снова Tag
010, Index10 - строка
10: Y, tag совпал - HIT
Состояние кэша после доступа 3: без изменений.
Доступ 4: LW 11010
- Tag
110, Index10 - в строке
10был tag010— не совпадает с110 - MISS (конфликт по индексу)
- вытеснить, загрузить \(W_{11010}\)
Состояние кэша после доступа 4:
| Block Index | Validity | Tag | Data |
|---|---|---|---|
| 00 | Y | 011 | \(W_{01100}\) |
| 01 | N | — | — |
| 10 | Y | 110 | \(W_{11010}\) |
| 11 | N | — | — |
Доступ 5: LW 01010
- разбор адреса: Tag
010, Index10 - строка
10: Validity Y, Tag110— не совпадает с010 - MISS (строка вытеснена на доступе 4)
- вытеснить \(W_{11010}\), снова загрузить \(W_{01010}\) в строку
10
Состояние кэша после доступа 5:
| Block Index | Validity | Tag | Data |
|---|---|---|---|
| 00 | Y | 011 | \(W_{01100}\) |
| 01 | N | — | — |
| 10 | Y | 010 | \(W_{01010}\) |
| 11 | N | — | — |
Сводка:
| Доступ | Адрес | Block Index | Tag | Итог | Причина |
|---|---|---|---|---|---|
| 1 | 01010 | 10 | 010 | MISS | строка невалидна |
| 2 | 01100 | 00 | 011 | MISS | строка невалидна |
| 3 | 01010 | 10 | 010 | HIT | tag совпал |
| 4 | 11010 | 10 | 110 | MISS | tag не совпал (конфликт) |
| 5 | 01010 | 10 | 010 | MISS | tag не совпал (строка была вытеснена) |
Conflict miss: 01010 и 11010 делят строку 10 и вытесняют друг друга — слабое место direct-mapped.
Ответ: Hit rate = 1/5 = 20%, Miss rate = 4/5 = 80%
3.2. Промах кэша при записи (Лекция 12, Пример 2)
Может ли быть cache miss у инструкции store (например SW 11010)? Что происходит?
Нажмите, чтобы увидеть решение
Ключевая идея: при store промах возможен; часто применяют write-allocate.
Ответ: да.
При SW 11010:
- разбор адреса на index и tag;
- поиск строки;
- при MISS: сначала подкачать целый блок (write-allocate), затем изменить нужное слово, пометить dirty;
- при HIT: правка в строке, dirty.
Зачем читать блок при промахе записи: кэш работает с blocks, не с отдельными словами; для согласованности и последующих load нужен полный блок.
Политики записи: write-through (всегда в RAM) и write-back (в RAM при вытеснении); чаще write-back + write-allocate.
3.3. Data hazard и forwarding (Лекция 12, Пример 3)
A: add x19, x0, x1
B: sub x2, x19, x3B зависит от x19, записываемого A. Объясните:
- почему это data hazard
- как forwarding снимает проблему
- что без forwarding
Нажмите, чтобы увидеть решение
Ключевая идея: результат ещё не в регистровом файле в нужный момент; forwarding подаёт его из конвейера.
(a) Почему возникает data hazard:
В 5-стадийном конвейере:
- инструкция A записывает
x19на стадии WB (такт 5); - инструкция B нуждается в
x19на стадиях ID (такт 3) и EX (такт 4).
Без мер B прочитает из register file старое значение x19 до записи нового — результат неверен.
| Такт | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| A: add | IF | ID | EX | MA | WB (пишет x19) |
| B: sub | IF | ID (нужен x19) | EX (нужен x19) | MA |
(b) Как forwarding снимает проблему:
Forwarding (также bypassing) — прямой путь данных с выхода одной стадии на вход другой.
- после EX у A (такт 3) результат уже в регистре конвейера EX/MEM;
- его можно forward на вход EX у B (такт 4);
- EX у B использует проброшенное значение, а не только чтение из register file.
| Такт | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| A: add | IF | ID | EX (считает x19) | MA | WB |
| B: sub | IF | ID | EX (использует forwarded x19) | MA |
Пауз stall не требуется — конвейер идёт без остановок.
(c) Без forwarding:
Процессор вынужден stall-ить B до завершения WB у A:
| Такт | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| A: add | IF | ID | EX | MA | WB | |||
| B: sub | IF | stall | stall | stall | ID | EX | MA |
B задерживается на три такта — сильно падает throughput; поэтому в процессорах строят развитые сети forwarding.
Ответ: forwarding позволяет не останавливать конвейер, пробрасывая результат между стадиями; по сравнению с наивным stall даёт типично примерно 2–3× ускорение.
3.4. Переупорядочивание компилятором (Лекция 12, Пример 4)
a = b + e;
c = b + f;Покажите переупорядочивание инструкций RISC-V, чтобы уменьшить stall. База переменных в x31.
Нажмите, чтобы увидеть решение
Ключевая идея: независимый load поднять между другими load и первым add, чтобы к моменту add операнды были готовы.
Исходный (наивный) ассемблер:
lw x1, 0(x31) // Load b
lw x2, 8(x31) // Load e
add x3, x1, x2 // a = b + e [STALL: waiting for x1, x2]
sw x3, 24(x31) // Store a
lw x4, 16(x31) // Load f
add x5, x1, x4 // c = b + f [STALL: waiting for x4]
sw x5, 32(x31) // Store cПроблема: add вынуждены ждать завершения соответствующих lw (load-use hazard).
Оптимизированный ассемблер:
lw x1, 0(x31) // Load b
lw x2, 8(x31) // Load e
lw x4, 16(x31) // Load f [MOVED UP!]
add x3, x1, x2 // a = b + e [No stall—x1, x2 ready]
sw x3, 24(x31) // Store a
add x5, x1, x4 // c = b + f [No stall—x1, x4 ready]
sw x5, 32(x31) // Store cПояснение:
- третий
lw x4, 16(x31)не зависит от предыдущих вычислений; - перенос сразу после двух первых
lwзаполняет окно задержки; - к первому
addвсе три загруженных значения уже готовы (в типичном конвейереloadзанимает порядка 2–3 тактов); - оба
addвыполняются без stall.
Оценка ускорения: было ~11–12 тактов со stall; стало ~7–8 без stall; прирост порядка 40–50%.
Ответ: переупорядочивание третьего lw перед первым add заполняет «дыру» после загрузок и убирает pipeline stalls, заметно повышая производительность.