W11. Архитектура набора команд RISC-V (ISA), программирование на ассемблере, трансляция программ
1. Краткое содержание
1.1 Знакомство с RISC-V
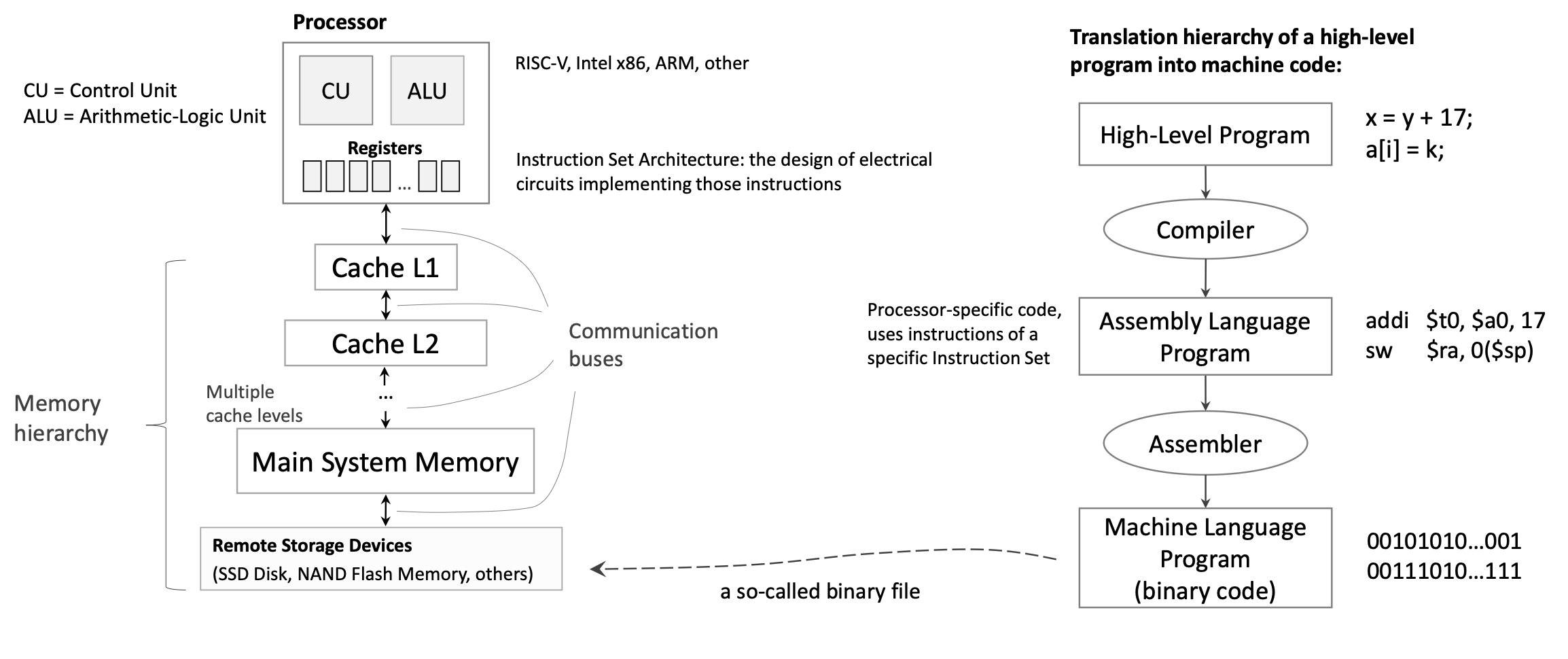
RISC-V (компьютер с сокращенным набором команд, 5-е поколение) — это современная архитектура набора команд (ISA), разработанная с учетом простоты и эффективности. В отличие от традиционных архитектур, которые могут иметь сотни сложных инструкций, RISC-V следует философии RISC: используйте небольшой набор простых инструкций, которые выполняются быстро. Этот принцип проектирования помогает минимизировать propagation delay (время прохождения сигнала по критическому пути), что напрямую влияет на clock frequency CPU и общую производительность.
Архитектура RISC-V представляет собой архитектуру загрузки/сохранения, означающую, что все вычислительные инструкции (такие как сложение, вычитание, логические операции) работают исключительно с регистрами — специальными высокоскоростными хранилищами, напрямую подключенными к вычислительным блокам процессора. Только специальные инструкции загрузки и сохранения могут передавать данные между регистрами и памятью. Такой выбор конструкции упрощает набор команд и обеспечивает более быстрое выполнение.
1.2 Регистры RISC-V
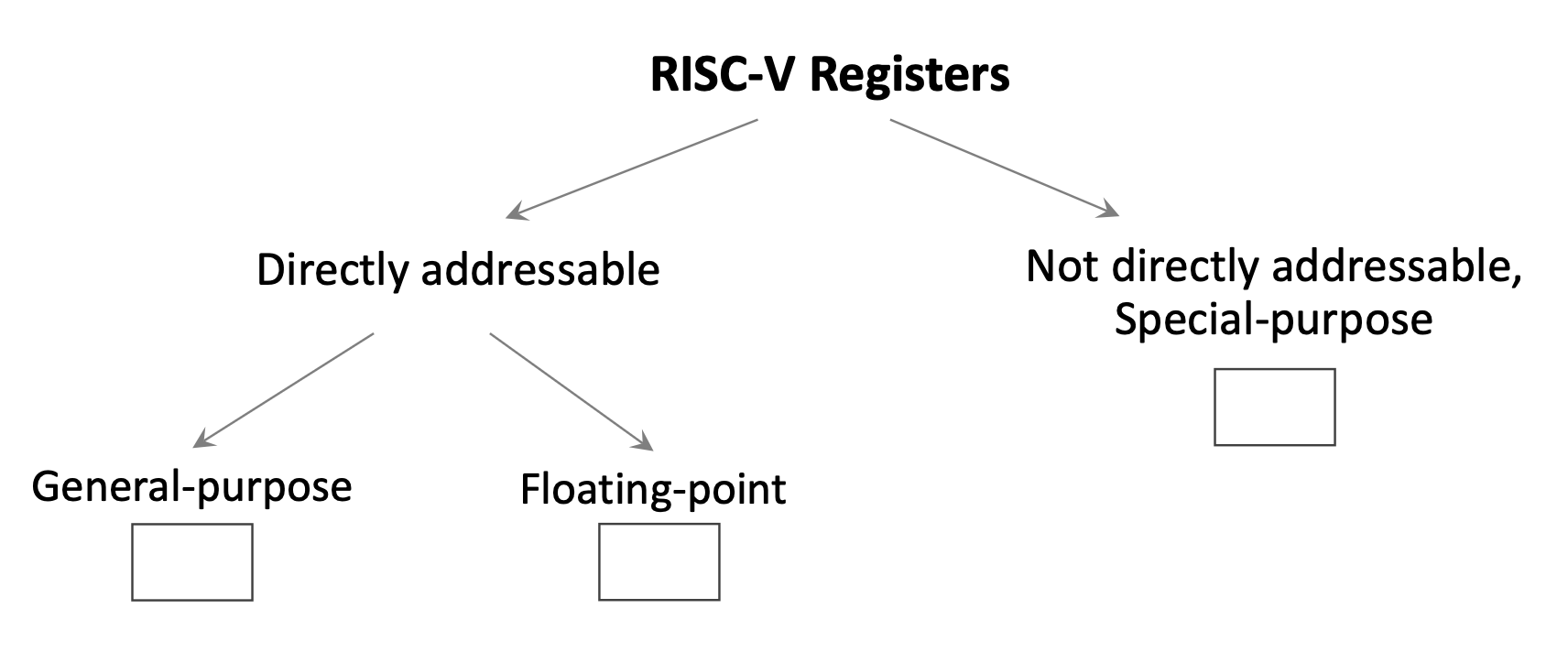
1.2.1 Целочисленные регистры общего назначения
RISC-V предоставляет 32 целочисленных регистра с прямой адресацией, с именами от «x0» до «x31». По умолчанию каждый регистр имеет ширину 64 бита (в RV64, 64-битном варианте RISC-V). Эти регистры являются общего назначения, но по соглашению они зарезервированы для конкретных целей, чтобы обеспечить согласованность между программами и облегчить вызовы функций. Каждый регистр имеет как числовое имя (например, «x5»), так и имя ABI (двоичный интерфейс приложения) (например, «t0»), которое описывает его обычное использование.
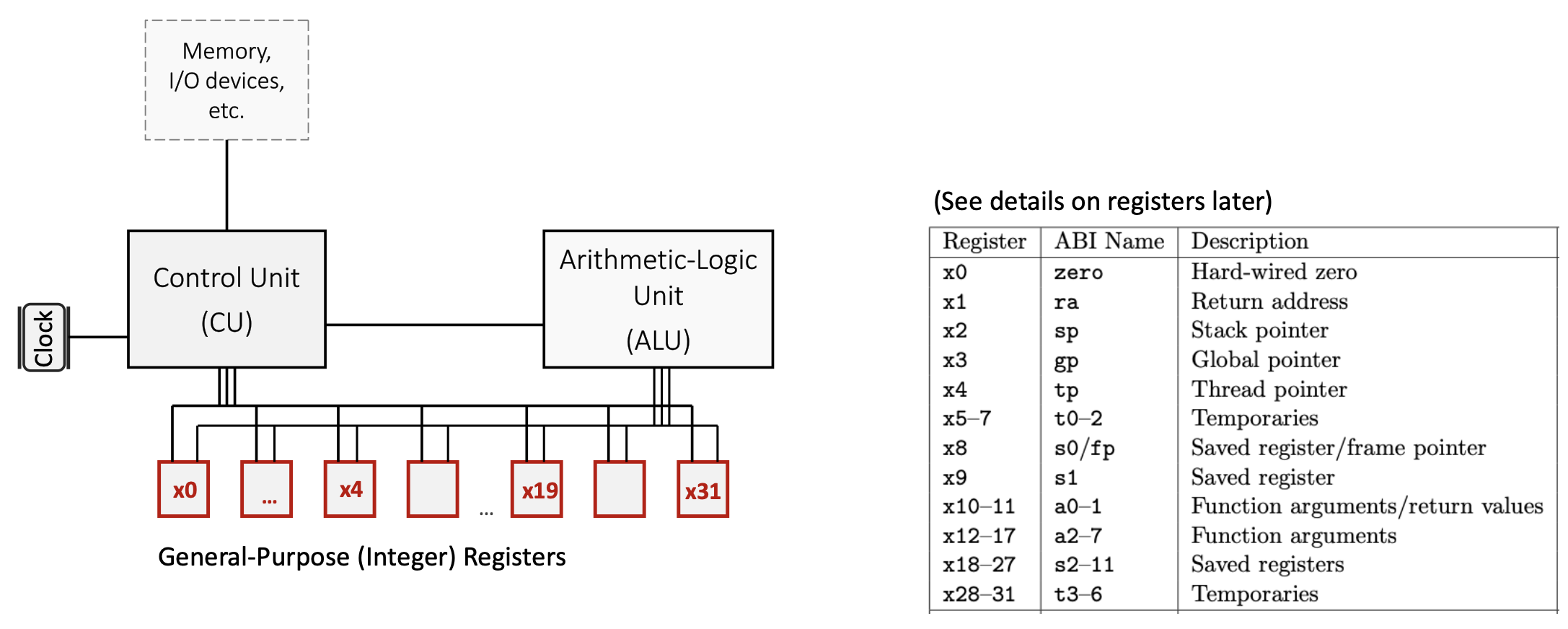
Категории ключевых регистров:
x0(ноль): специальный регистр, жестко привязанный к постоянному значению 0. Запись в этот регистр не имеет никакого эффекта, а чтение из него всегда возвращает 0. Это полезно для таких операций, как копирование значений (путем добавления нуля) или реализация инструкций NOP (без операций).- Временные регистры (
t0-t6): регистрыx5-x7иx28-x31используются для временных значений, которые не нужно сохранять при вызовах функций. Вызывающая сторона не ожидает, что эти значения останутся неизменными после вызова функции. - Сохраненные регистры (
s0-s11): регистрыx8-x9иx18-x27должны сохраняться при вызовах функций. Если функция использует эти регистры, она должна сохранить их исходные значения и восстановить их перед возвратом. - Регистры аргументов/возврата (
a0-a7): регистрыx10-x17передают аргументы функциям и возвращают результаты.a0иa1специально содержат возвращаемые значения. - Регистры специального назначения:
x1(ra): регистр Адрес возврата, хранит адрес для возврата после вызова функции.x2(sp): Stack pointer — указывает на вершину текущего кадра стека (top текущего stack frame).x3(gp): Глобальный указатель, обеспечивает доступ к глобальным/статическим переменным.x4(tp): указатель потока, используется в многопоточных программах.x8(s0/fp): также может служить указателем кадра для ссылки на локальные переменные.

1.2.2 Регистры специального назначения
Program Counter (PC) — специальный регистр в составе Control Unit (CU), который большинством инструкций напрямую не адресуется. В нём хранится адрес памяти текущей исполняемой инструкции; после выборки каждой команды PC обычно сдвигается на следующую.
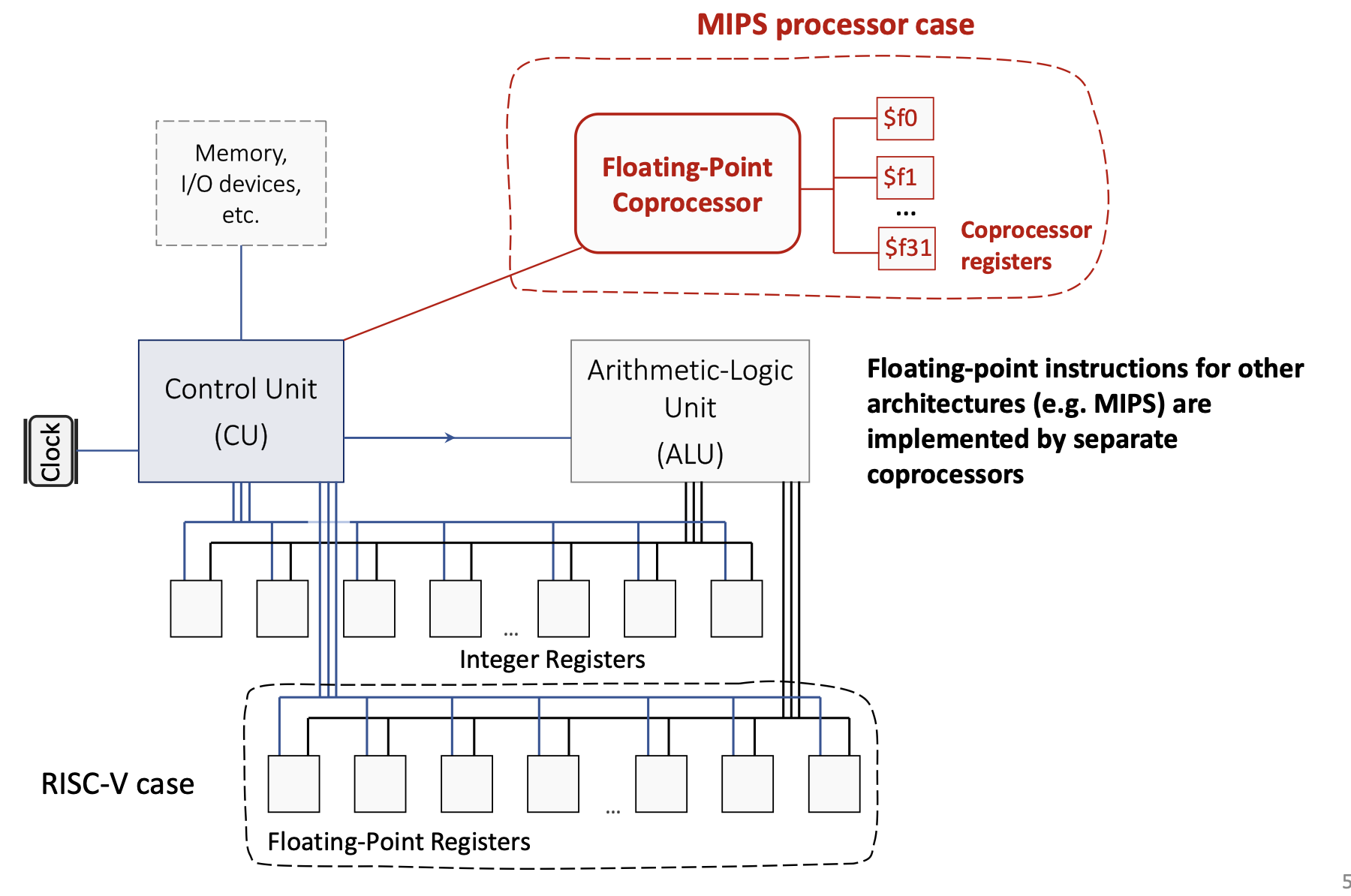
1.2.3 Регистры с плавающей запятой
RISC-V также включает 32 регистра с плавающей запятой (f0-f31) для операций с числами с плавающей запятой. В отличие от некоторых старых архитектур (например, MIPS, в которых использовался отдельный сопроцессор с плавающей запятой), RISC-V интегрирует поддержку операций с плавающей запятой непосредственно в основной процессор.
1.2.4 Register Spilling (вытеснение регистров)
Поскольку целочисленных регистров всего 32, в сложных программах со многими живыми переменными регистры могут закончиться. Тогда compiler выполняет register spilling: он временно сохраняет некоторые значения регистров в памяти (обычно в стеке), чтобы освободить регистры, а затем перезагружает их при необходимости. Это компромисс между стоимостью большего количества регистров (что приведет к увеличению сложности оборудования и задержки распространения) и периодическим снижением производительности при доступе к памяти. ##### 1.3 Компоненты архитектуры RISC-V ###### 1.3.1 Control Unit (CU)
Control Unit координирует все операции CPU:
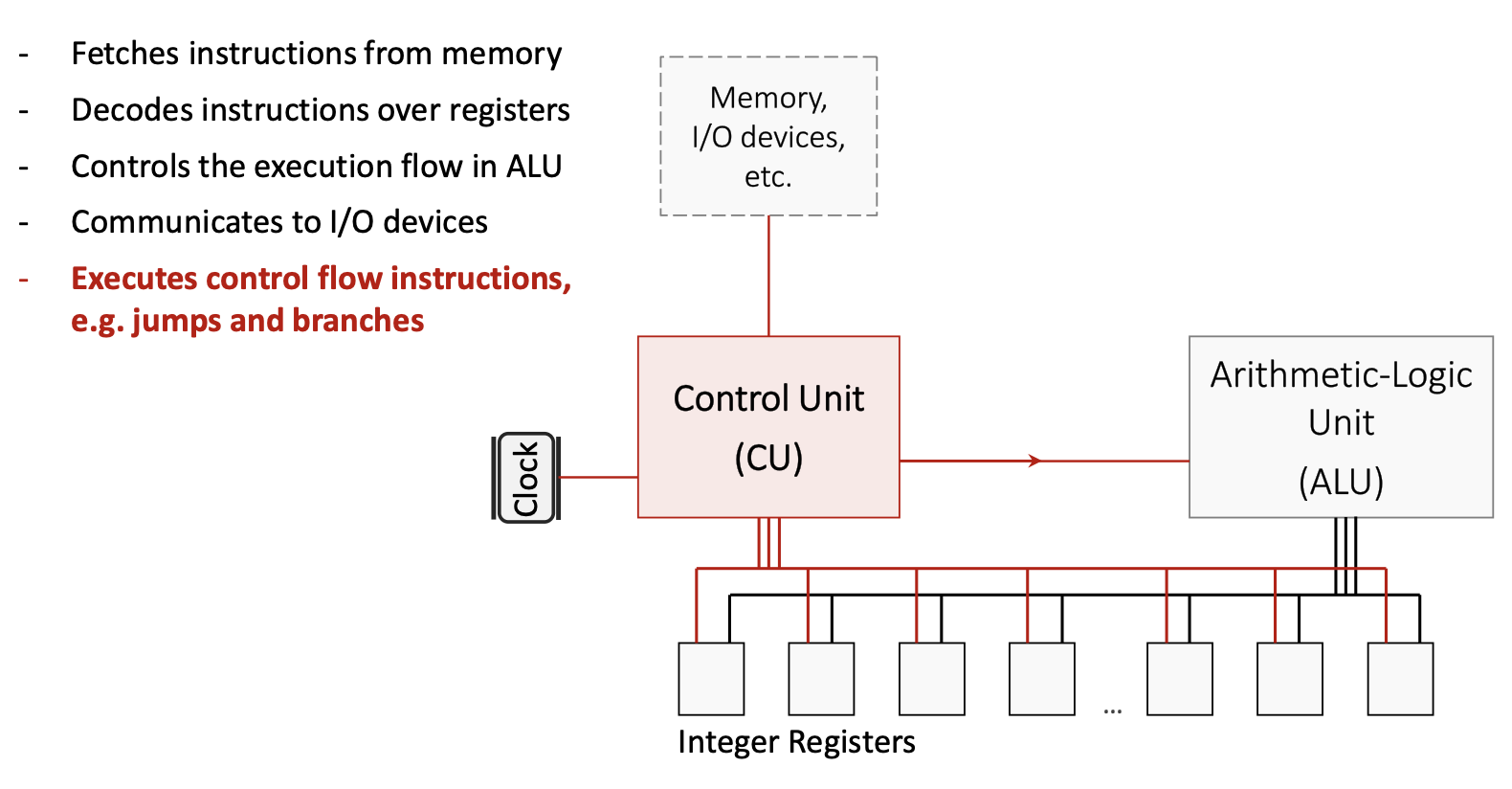
1.3.2 Arithmetic Logic Unit (ALU)
ALU выполняет все арифметические и логические вычисления:
- Выполняет такие операции, как сложение, вычитание, И, ИЛИ, исключающее ИЛИ и сдвиг битов.
- Спроектирован так, чтобы минимизировать propagation delay и тем самым допускать более высокую clock frequency.
- Получает операнды из регистров, выполняет операцию и записывает результат обратно в регистр.
1.3.3 Коммуникационные шины
On-chip communication buses соединяют CU, ALU, регистры и иерархию памяти. По этим шинам передают:
- Instruction data из памяти в CU
- Operand values между регистрами и ALU
- Управляющие сигналы, которые координируют операции между компонентами.
1.4 Категории инструкций RISC-V
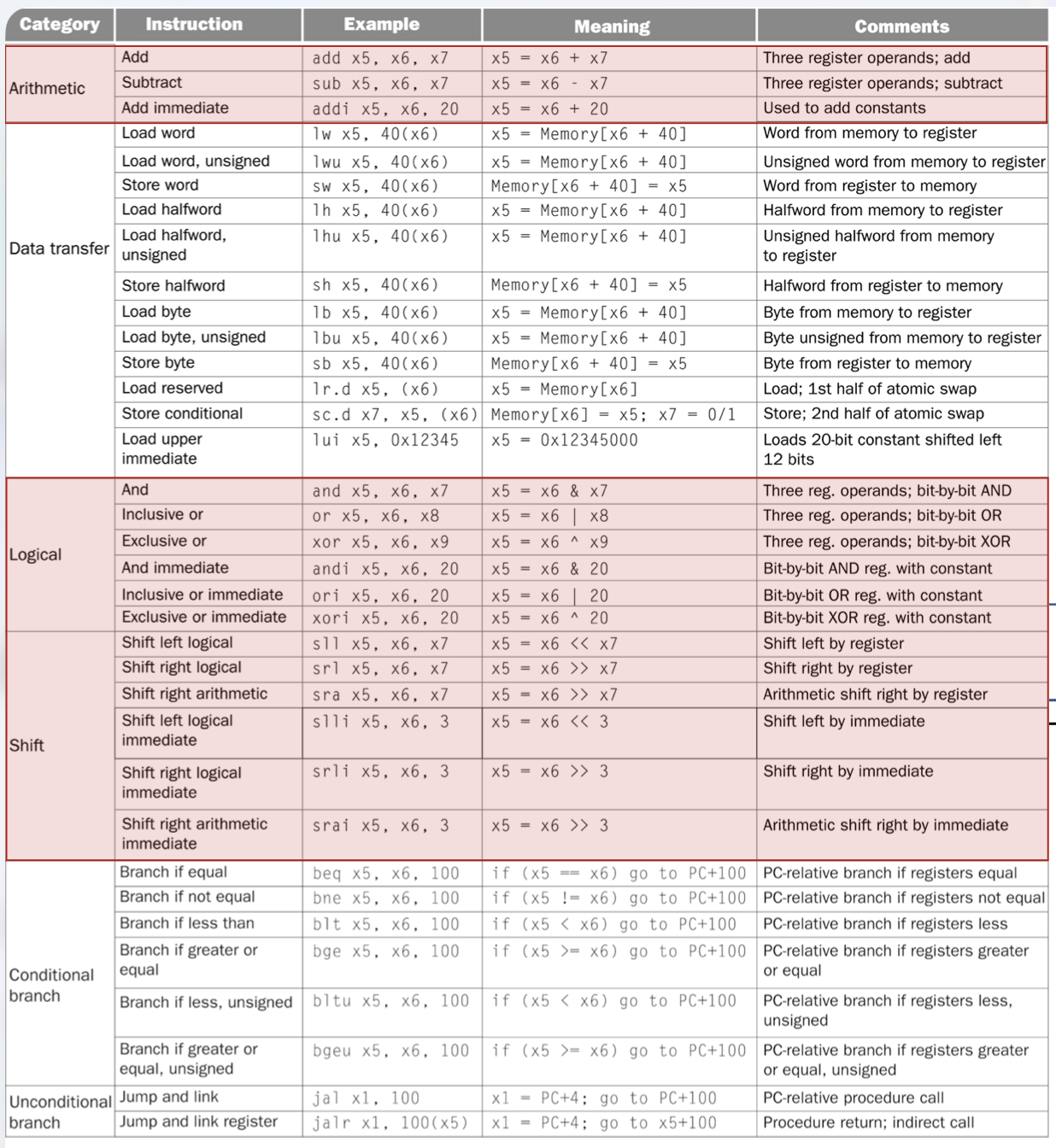
Инструкции RISC-V разделены на несколько категорий в зависимости от их функции:
1.4.1 Арифметические инструкции
Эти инструкции выполняют математические операции над значениями регистров:
add rd, rs1, rs2: складывает значения в регистрахrs1иrs2, сохраняет результат в регистреrd. Пример:add x5, x6, x7вычисляетx5 = x6 + x7.sub rd, rs1, rs2: вычитаетrs2изrs1, сохраняет результат вrd. Пример:sub x5, x6, x7вычисляетx5 = x6 - x7.addi rd, rs1, imm: добавляет немедленное (постоянное) значение кrs1, сохраняет результат вrd. Пример:addi x5, x6, 20вычисляетx5 = x6 + 20. Эта инструкция имеет решающее значение для загрузки констант и настройки адресов.
1.4.2 Логические инструкции
Они выполняют побитовые операции (работающие с каждым битом независимо):
and rd, rs1, rs2: побитовое И. Пример:and x5, x6, x7вычисляетx5 = x6 & x7.or rd, rs1, rs2: побитовое ИЛИ. Пример:or x5, x6, x8вычисляетx5 = x6 | x8.xor rd, rs1, rs2: побитовое исключающее ИЛИ (исключающее ИЛИ). Пример:xor x5, x6, x9вычисляетx5 = x6 ^ x9.- Непосредственные версии:
andi,ori,xoriвыполняют эти операции с постоянным значением.
1.4.3 Инструкции по сдвигу
Инструкции сдвига перемещают биты влево или вправо:
sll rd, rs1, rs2: логический сдвиг влево на величину вrs2. Пример:sll x5, x6, x7вычисляетx5 = x6 << x7. Это умножается на степени 2.srl rd, rs1, rs2: логический сдвиг вправо на величину вrs2. Заполняется нулями слева. Используется для беззнакового деления на степени 2.sra rd, rs1, rs2: сдвиг вправо на величину вrs2. Сохраняет знаковый бит для чисел со знаком.- Непосредственные версии:
slli,srli,sraiиспользуют постоянную величину сдвига (например,slli x5, x6, 3вычисляетx5 = x6 << 3).
1.4.4 Инструкции по передаче данных
Эти инструкции перемещают данные между регистрами и памятью:
- Инструкции по загрузке считываются из памяти в регистр:
lw rd, offset(rs1): Загрузочное слово (32 бита). Пример:lw x5, 40(x6)загружает слово по адресуx6 + 40вx5.lh rd, offset(rs1): загрузить полуслово (16 бит), расширенное по знаку до 64 бит.lb rd, offset(rs1): загрузочный байт (8 бит), расширенный по знаку до 64 бит.- Версии без знака (
lwu,lhu,lbu) имеют нулевое расширение вместо знакового расширения.
- Инструкции сохранения записывают из регистра в память:
sw rs2, offset(rs1): Сохранение слова. Пример:sw x5, 40(x6)сохраняет слово вx5по адресуx6 + 40.sh rs2, offset(rs1): сохранить полуслово.sb rs2, offset(rs1): сохранить байт.
lui rd, imm: Немедленно загрузить верхний уровень. Загружает 20-битную константу в старшие 20 битrd, обнуляя младшие 12 бит. Пример:lui x5, 0x12345устанавливаетx5 = 0x12345000. Используется в сочетании с другими инструкциями для загрузки больших констант.- Atomic instructions (
lr.d,sc.d): load-reserved и store conditional для синхронизации в многопоточных программах.
1.4.5 Инструкции условного перехода
Инструкции ветвления реализуют условное выполнение (например, операторы if):
beq rs1, rs2, offset: Branch if equal — еслиrs1 == rs2, переход наPC + offset. Пример:beq x5, x6, 100прыгает на 100 байт вперёд, еслиx5равенx6.bne rs1, rs2, offset: Branch if not equal.blt rs1, rs2, offset: Branch if less than (сравнение со знаком).bge rs1, rs2, offset: Branch if greater or equal (со знаком).bltu rs1, rs2, offset: Branch if less than (беззнаковое сравнение).bgeu rs1, rs2, offset: Branch if greater or equal (беззнаковое сравнение).
Все смещения ветвей являются относительными PC: они определяют смещение от текущего значения PC.
1.4.6 Инструкции безусловного перехода
Инструкции перехода реализуют вызовы функций и возвраты:
jal rd, offset: Jump and link — сохраняет адрес возврата (PC + 4) вrd, затем переходит наPC + offset. Пример:jal x1, 100кладёт адрес следующей инструкции вx1и прыгает на 100 байт вперёд; используется для вызова функций.jalr rd, offset(rs1): Jump and link register — сохраняетPC + 4вrd, затем переходит наrs1 + offset. Пример:jalr x1, 100(x5)сохраняет адрес возврата вx1и переходит наx5 + 100; нужен для косвенных вызовов и возврата из функции (в т.ч. сrd = x0, если адрес возврата не нужен).
1.5 Псевдоинструкции
Псевдоинструкции — это удобные мнемоники, которые ассемблер преобразует в одну или несколько реальных инструкций RISC-V. Они упрощают программирование на ассемблере:
li rd, imm: Load immediate. Пример:li t1, 5разворачивается вaddi t1, zero, 5.mv rd, rs: Move. Пример:mv a0, t0→add a0, zero, t0.nop: No operation →addi zero, zero, 0.la rd,symbol: Загрузить адрес символа (метки) вrd.j offset: переход становитсяjal x0, offset(переход без сохранения адреса возврата).ret: возврат из функции становитсяjalr x0, 0(ra)(переход по адресу вra).
1.6 Системные вызовы
System calls (syscalls) дают программе способ запросить услуги ОС, таких как операции ввода-вывода. В сборке RISC-V с использованием симулятора RARS системные вызовы вызываются с помощью инструкции ecall. Конкретная услуга определяется кодом, помещенным в регистр «a7», а аргументы передаются в регистры «a0», «a1» и т. д.
Общие коды системных вызовов:
- Код 1 (Печать целого числа): печатает целое значение в
a0на консоль. - Код 2 (Печать с плавающей запятой): печатает значение с плавающей запятой в
fa0на консоль. - Код 3 (Печать двойного значения): печатает двойное значение в
fa0на консоль. - Код 4 (Печатать строку): печатает строку с нулевым символом в конце, адрес которой находится в
a0. - Код 5 (Чтение целого числа): считывает целое число с консоли и сохраняет его в
a0. - Код 8 (Чтение строки): считывает строку в буфер по адресу
a0с максимальной длиной вa1. - Код 10 (Выход): Завершает программу.
Типичная схема использования:
li a7, 1 # Set syscall code to 1 (print integer)
li a0, 42 # Load value to print
ecall # Execute syscall1.7 Структура программы сборки
Программы сборки RISC-V разделены на сегменты:
1.7.1 Сегмент данных
Директива .data отмечает начало сегмента данных, который содержит статические переменные и константы:
.data
msg: .asciz "Hello, World!" # Null-terminated string
number: .word 42 # 32-bit integer
buffer: .space 100 # Reserve 100 bytes.asciz: объявляет строку, завершающуюся нулем..word: объявляет 32-битное целое число..space n: резервируетnбайт неинициализированного пространства.
1.7.2 Текстовый сегмент
Директива .text отмечает начало сегмента кода, содержащего исполняемые инструкции:
.text
main:
# Your code hereМетки (например, main:) отмечают определенные места в коде и могут использоваться в качестве целей перехода.
1.8 Написание программ на ассемблере RISC-V
Чтобы написать эффективную программу ассемблера:
- Понять алгоритм. Разбейте высокоуровневую логику на простые шаги.
- Выделение регистров: решите, какие регистры будут хранить какие значения. Используйте временные регистры (t0-t6) для промежуточных вычислений и сохраненные регистры (s0-s11) для значений, которые должны сохраняться.
- Загрузка констант: используйте
liдля загрузки непосредственных значений в регистры. - Выполнение вычислений. Используйте арифметические и логические инструкции.
- Обработка ввода-вывода: используйте системные вызовы для чтения входных данных и вывода на печать.
- Выход без ошибок: всегда завершайте системным вызовом выхода (
li a7, 10; ecall).
1.9 Процесс перевода программы
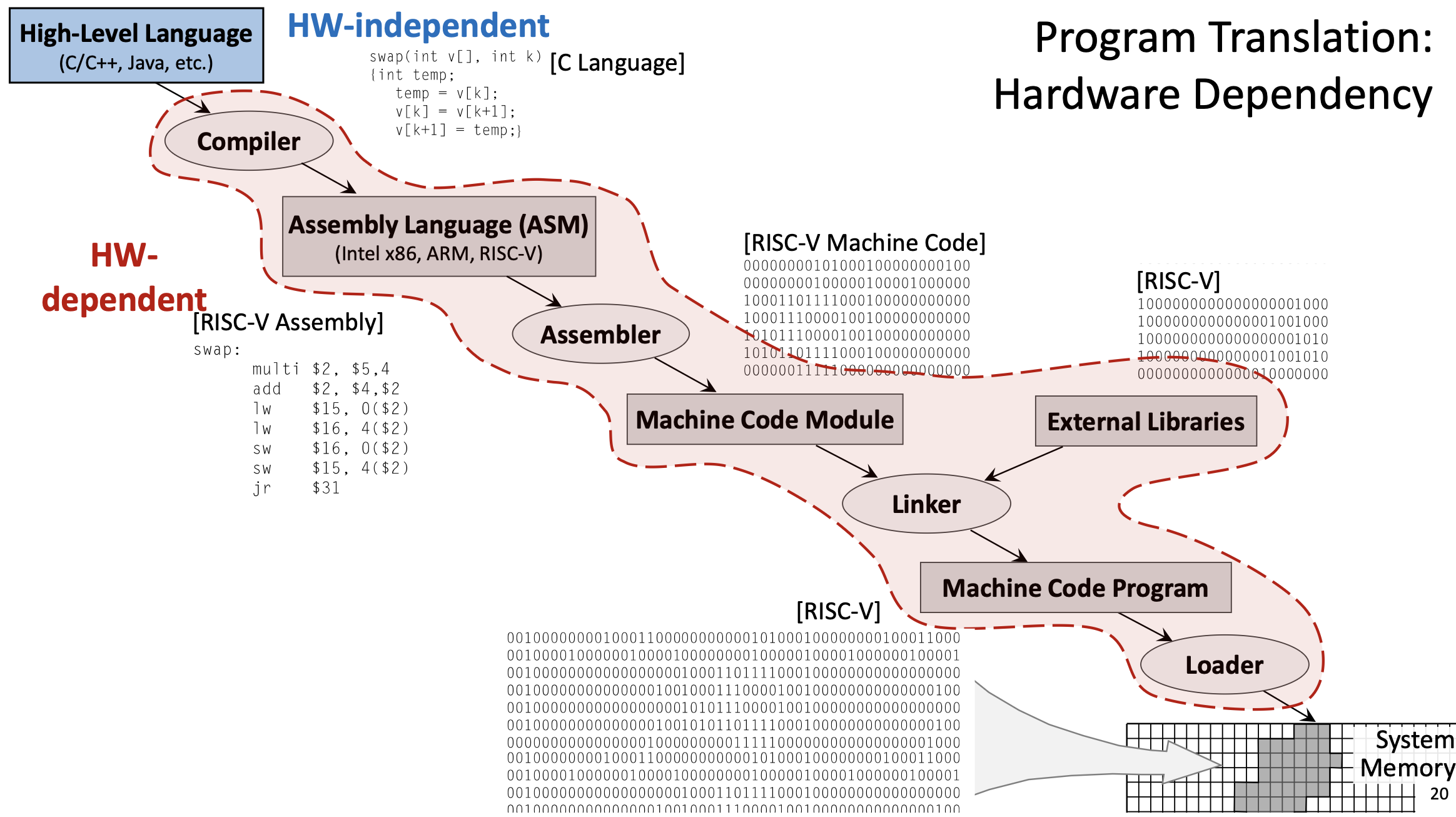
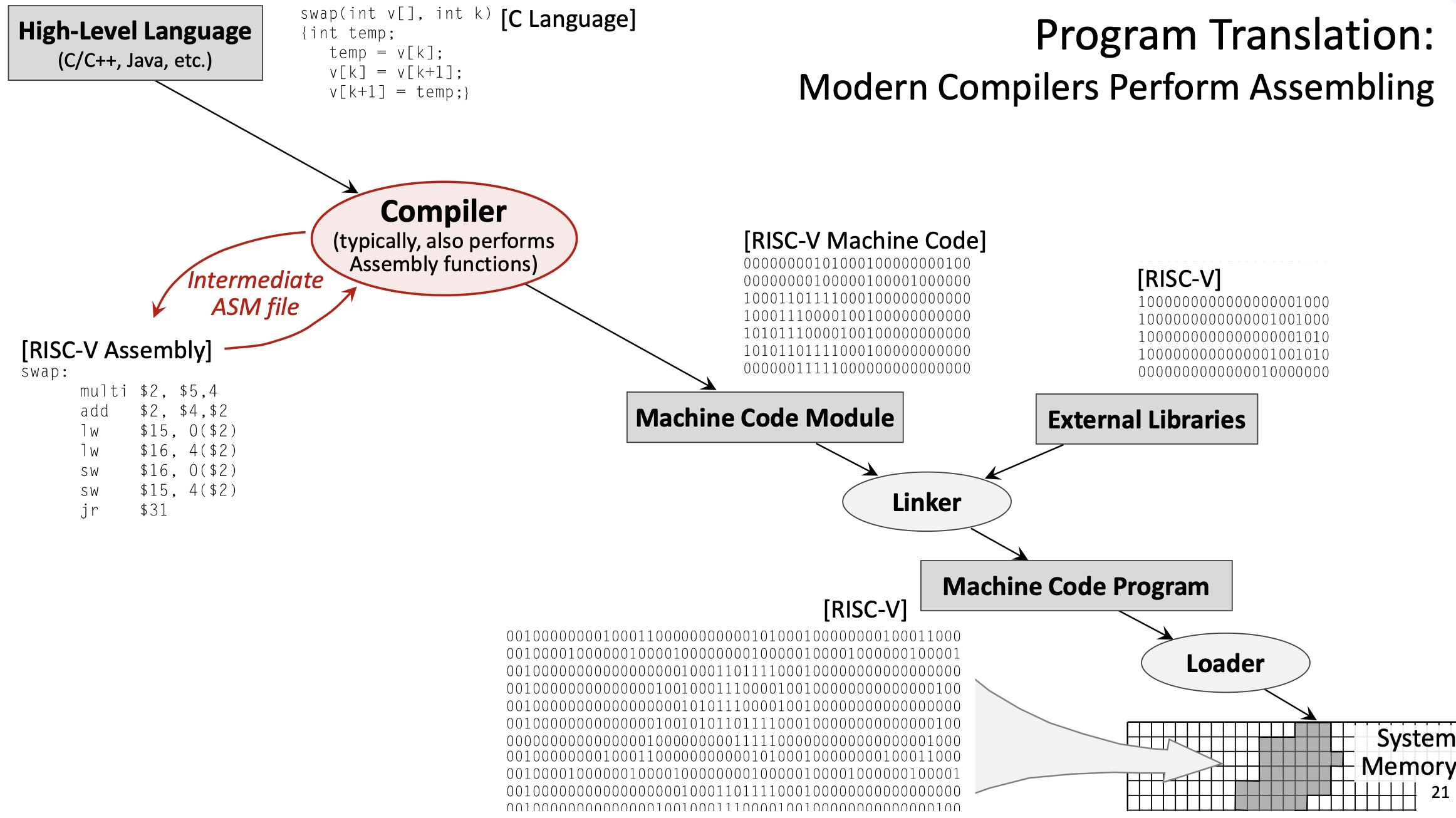
Прежде чем программа сможет работать на процессоре, ее необходимо перевести из исходного кода высокого уровня в машинный код. Этот процесс включает в себя несколько этапов:
1.9.1 Язык высокого уровня
Программы обычно пишутся на языках высокого уровня, таких как C, C++ или Java. Эти языки аппаратно-независимы: один и тот же исходный код теоретически может работать на любой процессорной архитектуре. Языки высокого уровня предоставляют такие абстракции, как переменные, функции, циклы и объекты, которые делают программирование более интуитивным.
Пример функции C:
void swap(int v[], int k) {
int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}1.9.2 Компиляция
Компилятор преобразует высокоуровневый код на язык ассемблера для конкретной целевой архитектуры (например, RISC-V, x86 или ARM). Этот этап сложен и включает в себя:
- Парсинг: анализ синтаксиса и семантики исходного кода.
- Оптимизация: применение преобразований для повышения производительности (например, устранение избыточных вычислений, изменение порядка инструкций, развертывание циклов).
- Генерация кода: создание ассемблерных инструкций, реализующих логику высокого уровня.
- Распределение регистров: принятие решения о том, какие переменные и в каких регистрах следует хранить.
Компилятор настраиваемый: вы можете указать уровни оптимизации (например, «-O0» для отсутствия оптимизации, «-O3» для агрессивной оптимизации) и языковые стандарты.
Пример вывода (упрощенная сборка RISC-V для функции swap):
swap:
slli t0, a1, 2 # t0 = k * 4 (multiply by word size)
add t0, a0, t0 # t0 = address of v[k]
lw t1, 0(t0) # t1 = v[k]
lw t2, 4(t0) # t2 = v[k+1]
sw t2, 0(t0) # v[k] = t2 (v[k+1])
sw t1, 4(t0) # v[k+1] = t1 (v[k])
jr ra # return1.9.3 Сборка
Ассемблер преобразует язык ассемблера в машинный код (двоичный). Это относительно простой механический процесс:
- Каждая ассемблерная инструкция соответствует определенной двоичной кодировке, определенной ISA.
- Метки преобразуются в адреса.
- Псевдоинструкции превращаются в настоящие инструкции.
Выходными данными является объектный файл (модуль машинного кода), который содержит двоичные инструкции, но может содержать неразрешенные ссылки на внешние функции или библиотеки.
Пример: add x5, x6, x7 может быть закодирован как 32-битное двоичное значение 00000000011100110000001010110011.
1.9.4 Связывание
Компоновщик объединяет несколько объектных файлов и внешние библиотеки (например, стандартную библиотеку C) в одну исполняемую программу:
- Разрешает ссылки на внешние функции (например,
printf,malloc). - Назначает конечные адреса памяти всему коду и данным.
- Создает полный исполняемый двоичный файл.
Внешние библиотеки обычно указываются в исходном коде с помощью директив #include (в C/C++) или операторов import (на других языках).
1.9.5 Загрузка
Загрузчик является частью операционной системы. При запуске программы загрузчик:
- Читает исполняемый файл с диска.
- Выделяет память для кода программы, данных и стека.
- Копирует программу в системную память.
- Настраивает начальную среду выполнения (например, инициализирует регистры, устанавливает PC на точку входа программы).
- Передает управление программе.
1.10 Аппаратная зависимость
Процесс перевода включает в себя как аппаратно-независимый, так и аппаратно-зависимый этапы:
- Независимость от оборудования: исходный код высокого уровня (C, Java и т. д.) может быть написан один раз и скомпилирован для разных архитектур.
- Зависит от оборудования: язык ассемблера, машинный код и конкретный используемый набор инструкций привязаны к конкретной архитектуре (RISC-V, x86, ARM и т. д.). Вы не можете запустить машинный код RISC-V на процессоре x86 без эмуляции.
Современные компиляторы часто выполняют также работу ассемблера, непосредственно создавая машинный код из исходного кода высокого уровня. Промежуточный файл сборки может быть создан для целей отладки, но это не является строго необходимым.
1.11 Архитектура и производительность набора команд
Конструкция ISA существенно влияет на производительность процессора:
1.11.1 Задержка распространения и тактовая частота
Наихудшая задержка распространения самой медленной команды определяет максимальную тактовую частоту. Если выполнение одной инструкции занимает намного больше времени, чем другие, весь процессор должен замедлиться, чтобы выполнить ее.
1.11.2 Количество регистров
Наличие большего количества регистров уменьшит потребность в доступе к памяти, но это имеет свои недостатки:
- Больше регистров → более сложные мультиплексоры и логика декодирования → более длинные задержки распространения → более низкая тактовая частота.
- Меньше регистров → более простое оборудование → более быстрые часы → но более частая утечка регистров (доступ к памяти).
32 регистра RISC-V представляют собой баланс: этого достаточно для большинства программ, чтобы хранить в регистрах часто используемые значения, но не так много, чтобы аппаратное обеспечение стало медленным. Целью разработки является оптимизация производительности для среднего варианта использования, а не только для лучшего или худшего варианта.
1.12 Иерархия памяти
Современные компьютеры используют иерархию памяти для баланса скорости и емкости:
- Регистры: самая быстрая (наносекунды), наименьшая емкость (32–64 регистра).
- Кэш L1: очень быстрый, небольшой (десятки КБ).
- Кэш L2: быстрый, средний (от сотен КБ до нескольких МБ).
- Основная системная память (ОЗУ): Медленнее, больше (ГБ).
- Удаленные устройства хранения данных (SSD, HDD): намного медленнее, очень большой размер (ТБ).
Инструкции и данные перемещаются вверх и вниз по этой иерархии по мере необходимости. ЦП всегда пытается сохранить наиболее часто используемые данные на более быстрых уровнях.
2. Определения
- RISC-V: компьютерная архитектура с сокращенным набором команд (5-го поколения), в которой для достижения высокой производительности используется небольшой набор простых и быстровыполняющихся инструкций.
- Архитектура набора инструкций (ISA): набор инструкций, которые может выполнять процессор, определяющий интерфейс между программным и аппаратным обеспечением.
- Регистр: место быстрого хранения, напрямую подключенное к вычислительным блокам ЦП и используемое для хранения операндов и результатов.
- Архитектура загрузки/сохранения: конструкция, в которой вычислительные инструкции работают только с регистрами, и только выделенные инструкции загрузки/сохранения имеют доступ к памяти.
- Имя ABI (двоичный интерфейс приложения): обычное имя регистра, указывающее его предназначение (например,
t0для временного,s0для сохранения). - Счетчик программ (ПК): специальный регистр, в котором хранится адрес памяти выполняемой в данный момент инструкции.
- Задержка распространения: время, необходимое сигналу для прохождения через цепь, определяющее максимальную тактовую частоту.
- Модуль управления (CU): компонент ЦП, который извлекает, декодирует и координирует выполнение инструкций.
- Arithmetic Logic Unit (ALU): часть CPU, выполняющая арифметику и логику по операндам команд.
- Псевдоинструкция: мнемоника ассемблера, которую ассемблер для удобства преобразует в одну или несколько реальных инструкций.
- Системный вызов (Syscall): механизм запроса программами служб операционной системы, таких как операции ввода-вывода.
- Разполнение регистров: процесс временного сохранения значений регистров в памяти, когда регистров недостаточно для всех действующих переменных.
- Компилятор: программа, которая преобразует исходный код высокого уровня в ассемблерный или машинный код для конкретной архитектуры.
- Ассемблер: программа, которая преобразует язык ассемблера в двоичный машинный код.
- Компоновщик: программа, объединяющая объектные файлы и библиотеки в одну исполняемую программу.
- Загрузчик: компонент операционной системы, который загружает исполняемые программы в память и инициирует выполнение.
- Объектный файл: файл, содержащий машинный код с потенциально неразрешенными внешними ссылками, созданный ассемблером.
- Независимый от оборудования: код или языки, которые могут работать на разных архитектурах процессоров без изменений (например, исходный код C).
- Зависит от оборудования: код или представления, привязанные к конкретной архитектуре процессора (например, сборка RISC-V, машинный код x86).
- Непосредственное значение: постоянное значение, закодированное непосредственно в инструкции (например,
20вaddi x5, x6, 20). - PC-Relative: режим адресации, в котором адреса указываются как смещения от текущего значения счетчика программ.
- Расширение знака: заполнение старших битов значения копиями бита знака для сохранения числового значения при преобразовании в больший размер.
- Расширение нуля: заполнение старших битов значения нулями при преобразовании в больший размер.
- Слово: 32-битная (4-байтовая) единица данных, стандартный размер для инструкций RISC-V.
- Полуслово: 16-битный (2-байтовый) блок данных.
- Байт: 8-битная единица данных.
3. Примеры
3.1. Простая программа сложения (Лаба 9, Задание 1)
Напишите ассемблерную программу RISC-V, которая вычисляет \(5 + 7\) и печатает результат.
Нажмите, чтобы увидеть решение
Ключевая концепция. Загружайте константы в регистры, выполняйте арифметические действия, используйте системные вызовы для вывода и корректно завершайте работу.
Вот программа, использующая псевдоинструкции:
li t1, 5 # load value "5" into register t1
li t2, 7 # load value "7" into register t2
add t0, t1, t2 # t0 = t1 + t2
mv a0, t0 # move value from register t0 to a0
li a7, 1 # set code for syscall to "1" (to print)
ecall # execute syscall with code in a7 and argument in a0
li a7, 10 # set code for syscall to "10" (exit)
ecall # execute syscall with code "10"Вот та же программа с псевдоинструкциями, расширенными до реальных инструкций RISC-V:
addi t1, zero, 5 # load value "5" into register t1 (li t1, 5)
addi t2, zero, 7 # load value "7" into register t2 (li t2, 7)
add t0, t1, t2 # t0 = t1 + t2
add a0, zero, t0 # move value from register t0 to a0 (mv a0, t0)
addi a7, zero, 1 # set code for syscall to "1" (li a7, 1)
ecall # execute syscall with code in a7 and argument in a0
addi a7, zero, 10 # set code for syscall to "10" (li a7, 10)
ecall # execute syscall with code "10"Пояснение:
- Константы загрузки:
li(немедленная загрузка) — это псевдоинструкция, которая становитсяadd rd,zero,imm. Мы загружаем 5 в «t1» и 7 в «t2». - Выполнить сложение:
add t0, t1, t2добавляет значения и сохраняет результат (12) вt0. - Подготовка к печати: нам нужно значение в
a0для системного вызова печати, поэтомуmv a0, t0копирует его (это становитсяadd a0,zero,t0). - Распечатка результата: установите
a7 = 1(код системного вызова для печати целого числа), затемecallвыполняет системный вызов, который печатает значение вa0. - Выход: установите
a7 = 10(код системного вызова для выхода), затемecallзавершит программу.
Ответ: Программа печатает 12 и завершает работу.
3.2. Чтение и печать строки (Лаба 9, Задание 2)
Напишите ассемблерную программу RISC-V, которая предлагает пользователю ввести строку, считывает ее и затем выводит ее обратно.
Нажмите, чтобы увидеть решение
Ключевая концепция. Используйте сегмент данных для статических строк и буферов. Используйте системные вызовы 4 (печать строки) и 8 (чтение строки).
.data # Start of segment with static variables
msg: .asciz "Enter your string: " # Prompt string
inputStr: .space 10 # Space for input string (10 bytes)
.text # Start of segment with code
main: # Start of the main function
li a7, 4 # Set code for syscall to PrintString
la a0, msg # Load address of msg to a0
ecall # Print the prompt
li a7, 8 # Set code for syscall to ReadString
la a0, inputStr # Load address of inputStr to a0
li a1, 10 # Set maximum read size to 10
ecall # Read the string
li a7, 4 # Set code for syscall to PrintString
la a0, inputStr # Load address of inputStr to a0
ecall # Print the input string
li a7, 10 # Set code for syscall to exit
ecall # Exit programПояснение:
- Сегмент данных:
msg— это метка строки приглашения, завершающейся нулем.inputStrрезервирует 10 байт для ввода пользователя.
- Запрос на печать:
- Установите
a7 = 4(системный вызов печати строки). - Используйте
la(адрес загрузки), чтобы поместить адресmsgвa0. ecallпечатает строку.
- Установите
- Читать ввод:
- Установите
a7 = 8(чтение строки системного вызова). - Поместите адрес
inputStrвa0(где хранить ввод). - Укажите максимальную длину (10) в
a1. ecallчитает строку из консоли.
- Установите
- Распечатайте введенные данные:
- Для печати снова установите
a7 = 4. - Поместите адрес
inputStrвa0. ecallпечатает то, что ввел пользователь.
- Для печати снова установите
- Выход: стандартная последовательность выхода.
Ответ: Программа запрашивает ввод, считывает до 10 символов и возвращает их обратно.
3.3. Сумма трех целых чисел (Лаб. 9, Задание 2)
Напишите ассемблерную программу RISC-V, которая считывает три целочисленных ввода от пользователя, вычисляет их сумму и отображает результат.
Нажмите, чтобы увидеть решение
Ключевая концепция. Трижды используйте системный вызов 5 (прочитать целое число), сложите значения, затем используйте системный вызов 1 (выведите целое число) для отображения результата.
.text
main:
# Read first integer
li a7, 5 # Syscall code for ReadInteger
ecall # Read integer, result stored in a0
mv t0, a0 # Save first integer in t0
# Read second integer
li a7, 5 # Syscall code for ReadInteger
ecall # Read integer, result stored in a0
mv t1, a0 # Save second integer in t1
# Read third integer
li a7, 5 # Syscall code for ReadInteger
ecall # Read integer, result stored in a0
mv t2, a0 # Save third integer in t2
# Compute sum
add t3, t0, t1 # t3 = t0 + t1 (sum of first two)
add t3, t3, t2 # t3 = t3 + t2 (add third number)
# Print result
mv a0, t3 # Move sum to a0 for printing
li a7, 1 # Syscall code for PrintInteger
ecall # Print the sum
# Exit
li a7, 10 # Syscall code for Exit
ecall # Exit programПояснение:
- Читать первое целое число:
- Установите
a7 = 5(чтение целочисленного системного вызова). ecallсчитывает целое число и сохраняет его вa0.- Сохраните его в
t0, используяmv t0, a0.
- Установите
- Читать второе целое число:
- Тот же процесс, сохраните в
t1.
- Тот же процесс, сохраните в
- Прочитайте третье целое число:
- Тот же процесс, сохраните в
t2.
- Тот же процесс, сохраните в
- Вычислить сумму:
add t3, t0, t1вычисляет сумму первых двух чисел.add t3, t3, t2добавляет третье число, чтобы получить окончательную сумму.
- Распечатать результат:
- Переместите сумму в
a0(требуется для системного вызова печати). - Установите
a7 = 1(выведите целое число). ecallпечатает результат.
- Переместите сумму в
- Выход: стандартная последовательность выхода.
Ответ: Программа считывает три целых числа, вычисляет их сумму, печатает ее и завершает работу. Например, если пользователь вводит 5, 10 и 15, программа печатает 30.
3.4. Перевод функции обмена (Лекция 9, Пример 1)
Учитывая следующую функцию C, покажите полный процесс перевода из кода высокого уровня в машинный код:
void swap(int v[], int k) {
int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}Нажмите, чтобы увидеть решение
Ключевая концепция. Понимание многоэтапного перевода с языка высокого уровня через ассемблер в двоичный машинный код.
Этап 1: Язык высокого уровня (C)
Функция C меняет местами два соседних элемента целочисленного массива. Это:
- Принимает массив
vи индексkв качестве параметров. - Использует временную переменную для выполнения замены
- Доступ к элементам массива с использованием скобок.
Этап 2: Компиляция в сборку
Компилятор преобразует это в ассемблер RISC-V. Предполагая:
a0содержит базовый адрес массиваva1содержит значениеk
swap:
slli t0, a1, 2 # t0 = k * 4 (multiply by word size)
add t0, a0, t0 # t0 = address of v[k]
lw t1, 0(t0) # t1 = v[k] (load first element)
lw t2, 4(t0) # t2 = v[k+1] (load second element)
sw t2, 0(t0) # v[k] = t2 (store second into first position)
sw t1, 4(t0) # v[k+1] = t1 (store first into second position)
jr ra # return (jump to return address)Пояснение ассемблерного кода: 1. Вычислить адрес: поскольку каждое целое число имеет длину 4 байта (1 слово), v[k] находится по адресу base + k*4. slli (немедленный логический сдвиг влево) эффективно умножает k на 4. 2. Добавить базовый адрес: add t0, a0, t0 вычисляет абсолютный адрес v[k]. 3. Загрузка значений: Загрузите v[k] и v[k+1] во временные регистры. 4. Сохранение замененных значений: запишите их обратно в обратном порядке. 5. Возврат: переход к адресу в ra (регистр адреса возврата).
Этап 3: Сборка в машинный код
Ассемблер преобразует каждую инструкцию в 32-битную двоичную кодировку. Пример кодировки (упрощённый):
slli t0, a1, 2 → 00000000001001011001001010010011
add t0, a0, t0 → 00000000010101010000001010110011
lw t1, 0(t0) → 00000000000000101010001100000011
lw t2, 4(t0) → 00000000010000101010001110000011
sw t2, 0(t0) → 00000000011100101010000000100011
sw t1, 4(t0) → 00000000011000101010001000100011
jr ra → 00000000000000001000000001100111В результате создается модуль машинного кода (объектный файл).
Этап 4. Установление связи
Компоновщик:
- Объединяет этот объектный файл с другими и внешними библиотеками.
- Разрешает любые ссылки на внешние функции.
- Назначает конечные адреса памяти
- Создает полный исполняемый двоичный файл
Этап 5. Загрузка
Загрузчик операционной системы:
- Выделяет память для программы
- Копирует машинный код в ОЗУ
- Настраивает исходное окружение (стек, регистры, ПК)
- Передает управление точке входа в программу
Ответ: В процессе трансляции функция C преобразуется посредством компиляции (в ассемблер), сборки (в двоичный объектный код), компоновки (в исполняемый файл) и загрузки (в память для выполнения). Каждый этап необходим для преобразования удобочитаемого кода в инструкции, которые процессор может выполнить.
3.5. Использование загрузки Upper Immediate (Лекция 9, Пример 2)
Загрузите 32-битное значение «0x12345678» в регистр «t0».
Нажмите, чтобы увидеть решение
Ключевая концепция: Инструкции RISC-V имеют размер 32 бита, поэтому размер непосредственных значений ограничен. Для загрузки больших констант мы используем lui (непосредственная загрузка верхнего уровня) в сочетании с addi или ori.
Метод:
- Загрузка старших 20 бит:
luiнемедленно загружает 20-битное значение в старшие 20 бит регистра и обнуляет нижние 12 бит. - Установить младшие 12 битов: используйте
addiилиori, чтобы установить младшие биты.
lui t0, 0x12345 # Load 0x12345 into upper 20 bits: t0 = 0x12345000
ori t0, t0, 0x678 # OR with 0x678: t0 = 0x12345000 | 0x678 = 0x12345678Пояснение:
lui t0, 0x12345:- Берет 20-битное значение
0x12345и помещает его в биты [31:12]t0. - Устанавливает биты [11:0] в ноль.
- Результат:
t0 = 0x12345000
- Берет 20-битное значение
ori t0, t0, 0x678:- Выполняет побитовое ИЛИ с 12-битным значением
0x678. - Поскольку старшие биты
0x678равны нулю, это фактически устанавливает младшие 12 бит. - Результат:
t0 = 0x12345678
- Выполняет побитовое ИЛИ с 12-битным значением
Альтернативный вариант использования addi:
lui t0, 0x12345 # t0 = 0x12345000
addi t0, t0, 0x678 # t0 = t0 + 0x678 = 0x12345678
```Это работает, когда младшие 12 бит не требуют расширения знака. Для отрицательных значений или когда установлен бит 11, вам может потребоваться настроить значение lui.
**Ответ:** Используйте lui для загрузки старших 20 бит, затем `ori` или `addi` для установки младших 12 бит.
</details>
##### **3.6. Доступ к массиву с помощью инструкции загрузки** (Лекция 9, Пример 3)
Учитывая целочисленный массив «A» с базовым адресом, хранящимся в регистре «s0», и индексом «i», хранящимся в регистре «s1», напишите инструкции для загрузки «A[i]» в регистр «t0».
<details>
<summary>Нажмите, чтобы увидеть решение</summary>
**Ключевая концепция.** Элементы массива хранятся в памяти последовательно. Для целочисленного массива каждый элемент имеет длину 4 байта (1 слово). Чтобы получить доступ к `A[i]`, вычислите `address = base + i * 4`.
**Решение:**```assembly
slli t1, s1, 2 # t1 = i * 4 (shift left by 2 is multiply by 4)
add t1, s0, t1 # t1 = base_address + offset = address of A[i]
lw t0, 0(t1) # t0 = Memory[t1] = A[i]Пояснение:
- Вычисление смещения:
slli t1, s1, 2сдвигаетiвлево на 2 бита, эффективно умножая на \(2^2 = 4\). Это вычисляет смещение в байтах для элементаi. - Вычислить адрес:
add t1, s0, t1добавляет базовый адрес к смещению, давая абсолютный адресA[i]. - Загрузить значение:
lw t0, 0(t1)загружает слово по адресуt1 + 0вt0.
Оптимизированный вариант (если смещение небольшое):
Если вы можете вычислить адрес за один шаг:
slli t1, s1, 2 # t1 = i * 4
add t1, s0, t1 # t1 = address of A[i]
lw t0, 0(t1) # t0 = A[i]
```Или, если использовать комбинированный подход:
```assembly
slli t1, s1, 2 # t1 = i * 4
lw t0, 0(s0 + t1) # ERROR: This syntax isn't valid!Примечание. RISC-V не поддерживает адресацию регистр+регистр напрямую в инструкциях загрузки/сохранения. Сначала вы должны вычислить адрес.
Ответ: Сдвиньте индекс влево на 2, чтобы умножить его на 4, прибавьте к базовому адресу, затем используйте lw для загрузки значения.
3.7. Пример условного перехода (Лекция 9, Пример 4)
Реализуйте следующий код C в сборке RISC-V:
if (x == y) {
z = x + y;
} else {
z = x - y;
}
```Предположим, что `x` находится в регистре `s0`, `y` находится в регистре `s1`, а `z` должен храниться в регистре `s2`.
<details>
<summary>Нажмите, чтобы увидеть решение</summary>
**Ключевая концепция.** Используйте инструкции условного перехода для реализации логики if-else. Инструкции ветвления проверяют условие и переходят к метке, если условие истинно.
**Решение:**```assembly
bne s0, s1, else_branch # If x != y, branch to else_branch
# Then branch (x == y)
add s2, s0, s1 # z = x + y
j end_if # Jump to end (skip else part)
else_branch:
sub s2, s0, s1 # z = x - y
end_if:
# Continue with rest of programПояснение:
- Проверка условия:
bne s0, s1, else_branch(ветвь, если не равна) проверяет,x != y. Если они не равны, происходит переход к else_branch. Если они равны, происходит переход к следующей инструкции. - Затем блок: Если
x == y, выполнитеadd s2, s0, s1, чтобы вычислитьz = x + y. - Пропустить else: после блока then
j end_if(безусловный переход) пропускает блок else. - Блок Else: Метка else_branch отмечает начало кода else. Выполните
sub s2, s0, s1, чтобы вычислитьz = x - y. - Продолжить: метка
end_ifотмечает место схождения обеих ветвей.
Альтернативный вариант использования beq:
beq s0, s1, then_branch # If x == y, branch to then_branch
# Else branch (x != y)
sub s2, s0, s1 # z = x - y
j end_if # Jump to end
then_branch:
add s2, s0, s1 # z = x + y
end_if:
# Continue
```Оба подхода верны; выбор зависит от того, какая ветвь, по вашему мнению, будет более распространенной (для оптимизации производительности).
**Ответ:** Используйте `bne` или `beq`, чтобы проверить условие, с метками, обозначающими блоки then и else, и переходом для пропуска неиспользуемой ветки.
</details>
##### **3.8. Пример простого цикла** (Лекция 9, Пример 5)
Реализуйте следующий цикл C в сборке RISC-V:
```c
int sum = 0;
for (int i = 0; i < 10; i++) {
sum = sum + i;
}
```Предположим, что сумма находится в регистре s0, а i — в регистре t0.
<details>
<summary>Нажмите, чтобы увидеть решение</summary>
**Ключевая концепция.** Циклы используют условные переходы для повторения кода. Типичный шаблон: инициализация, проверка условия, выполнение тела, приращение, повтор.
**Решение:**```assembly
li s0, 0 # sum = 0 (initialize sum)
li t0, 0 # i = 0 (initialize loop counter)
li t1, 10 # t1 = 10 (loop limit)
loop_start:
bge t0, t1, loop_end # If i >= 10, exit loop
add s0, s0, t0 # sum = sum + i
addi t0, t0, 1 # i = i + 1 (increment counter)
j loop_start # Jump back to start of loop
loop_end:
# sum now contains 0+1+2+...+9 = 45Пояснение:
- Инициализируйте переменные: установите
sum = 0иi = 0. Загрузите предел (10) вt1. - Условие проверки:
bge t0, t1,loop_end(переход, если больше или равно) проверяет,i >= 10. Если это правда, выйдите из цикла, перейдя к «loop_end». - Тело цикла: выполните
add s0, s0, t0, чтобы добавить текущее значениеiкsum. - Приращение:
addi t0, t0, 1увеличиваетiна 1. - Повторить:
jloop_startпереходит обратно к началу цикла. - Выход: когда условие становится истинным, выполняется переход к
loop_endи цикл завершается.
Результат: после цикла s0 содержит \(0 + 1 + 2 + \cdots + 9 = 45\).
Альтернативный вариант использования blt (проверка i < 10):
li s0, 0 # sum = 0
li t0, 0 # i = 0
li t1, 10 # limit
loop_start:
blt t0, t1, loop_body # If i < 10, continue
j loop_end # Otherwise exit
loop_body:
add s0, s0, t0 # sum = sum + i
addi t0, t0, 1 # i++
j loop_start # Repeat
loop_end:
# DoneОтвет: Используйте инструкцию ветвления, чтобы проверить состояние цикла, перейти к телу цикла, если оно истинно, увеличить счетчик и вернуться к началу. Выйдите, когда условие станет ложным.
3.9. Пример вызова функции (Лекция 9, Пример 6)
Напишите простую функцию RISC-V, которая принимает два целых числа в качестве аргументов, возвращает их сумму и показывает, как вызвать ее из другой функции.
Нажмите, чтобы увидеть решение
Ключевая концепция: При вызовах функций используются регистры a0–a7 для аргументов и возвращаемых значений, а также регистр ra для адреса возврата. Используйте jal для вызова функции и jr ra для возврата.
Определение функции (добавляет два целых числа):
# Function: add_two
# Arguments: a0 = first number, a1 = second number
# Returns: a0 = sum
add_two:
add a0, a0, a1 # a0 = a0 + a1 (compute sum)
jr ra # Return to caller
```**Вызов функции**:
```assembly
main:
# Prepare arguments
li a0, 15 # First argument = 15
li a1, 27 # Second argument = 27
# Call function
jal ra, add_two # Call add_two, save return address in ra
# Result is now in a0
# Print result
# (a0 already contains the result)
li a7, 1 # Syscall: print integer
ecall # Print the sum (42)
# Exit
li a7, 10 # Syscall: exit
ecallПояснение:
- Подготовьте аргументы: загрузите значения 15 и 27 в
a0иa1соответственно. Это стандартные регистры для передачи первых двух аргументов функции. - Вызов функции:
jal ra, add_twoделает две вещи:- Сохраняет адрес возврата (адрес следующей инструкции) в
ra. - Переход к метке
add_two.
- Сохраняет адрес возврата (адрес следующей инструкции) в
- Выполнение функции: Внутри
add_two:add a0, a0, a1вычисляет сумму и сохраняет ее вa0(стандартный регистр возвращаемого значения).jr ra(регистр перехода) переходит к адресу, хранящемуся вra, возвращаясь к вызывающей стороне.
- Использовать результат: после возврата функции
a0содержит результат (42). Мы можем использовать его непосредственно для системного вызова печати.
Более сложный пример (сохранение и восстановление регистров):
Если функции необходимо использовать регистры, которые необходимо сохранить (s0-s11, ra), она должна сохранить их в стеке:
# Function that uses saved registers
complex_function:
# Save registers
addi sp, sp, -8 # Allocate 8 bytes on stack
sw s0, 0(sp) # Save s0
sw ra, 4(sp) # Save return address
# Function body (use s0, call other functions, etc.)
li s0, 100
add a0, a0, s0
# Restore registers
lw s0, 0(sp) # Restore s0
lw ra, 4(sp) # Restore return address
addi sp, sp, 8 # Deallocate stack space
jr ra # ReturnОтвет: Используйте регистры a0-a7 для аргументов и возвращаемых значений. Вызывайте функции с помощью jal, который сохраняет адрес возврата в ra. Вернитесь с jr ra. При необходимости сохраните и восстановите сохраненные регистры, используя стек.
3.10. Понимание флагов компиляции (Лекция 9, Пример 7)
Объясните, как различные уровни оптимизации компилятора могут повлиять на сборку RISC-V, созданную для следующего кода C:
int sum = 0;
for (int i = 0; i < 1000; i++) {
sum += i;
}
return sum;Нажмите, чтобы увидеть решение
Ключевая концепция. Компиляторы могут применять различные оптимизации для повышения производительности. Более высокие уровни оптимизации создают более быстрый код, но могут затруднить отладку.
При -O0 (без оптимизации):
Компилятор генерирует простую сборку, которая точно отражает код C:
assembly li s0, 0 # sum = 0 li t0, 0 # i = 0 li t1, 1000 # limit = 1000 loop: bge t0, t1, end # if (i >= 1000) break add s0, s0, t0 # sum += i addi t0, t0, 1 # i++ j loop # repeat end: mv a0, s0 # return sum retПри этом выполняется 1000 итераций, выполняющих 1000 сложений.
При -O1 или -O2 (умеренная оптимизация):
Компилятор может применить такие оптимизации, как:
- Развертывание цикла: выполнение нескольких итераций за цикл цикла.
- Распределение регистров: используйте регистры более эффективно.
- Instruction reordering: упорядочьте инструкции так, чтобы уменьшить pipeline stalls.
assembly li s0, 0 # sum = 0 li t0, 0 # i = 0 li t1, 1000 # limit = 1000 loop: bge t0, t1, end # if (i >= 1000) break add s0, s0, t0 # sum += i addi t0, t0, 1 # i++ add s0, s0, t0 # sum += i (unrolled iteration) addi t0, t0, 1 # i++ j loop # repeat end: mv a0, s0 # return sum retЭто уменьшает накладные расходы цикла за счет обработки двух итераций за цикл.
При -O3 (агрессивная оптимизация):
Компилятор может распознать математическую закономерность. Сумма \(0 + 1 + 2 + \cdots + 999\) равна \(\frac{n(n-1)}{2}\), где \(n = 1000\):
\[\text{sum} = \frac{1000 \times 999}{2} = 499500\]
Компилятор мог бы заменить весь цикл константой:
assembly li a0, 499500 # return 499500 (computed at compile time!) retЭто постоянное свертывание: компилятор оценивает цикл во время компиляции и заменяет его результатом. Код выполняется мгновенно, без какого-либо цикла!
Компромиссы:
-O0: легко отлаживать (код точно соответствует исходному коду), но медленнее.-O2: хороший баланс скорости и размера кода.-O3: максимальная скорость, но больший размер кода, более длительное время компиляции, сложнее отладка.
Ответ: Более высокие уровни оптимизации могут существенно изменить код. Компилятор может разворачивать циклы, переупорядочивать инструкции или даже полностью исключать циклы посредством математического анализа. В этом случае -O3 может вычислить результат во время компиляции, создав всего одну инструкцию для загрузки константы.